Capitolo 2 Analisi grafiche
L’analisi grafica permette di prendere “un’istantanea” della distribuzione dei dati, e quindi di riconoscere pattern e/o identificare outlier.
Negli esempi che seguono genereremo grafici principalmente utilizzando il package ggplot2 (o più semplicemente ggplot), che si sta imponendo come uno standard di fatto per la gran parte delle rappresentazioni grafiche non tridimensionali.
Carichiamo il package ggplot2 e consideriamo quindi il dataset iris delle lunghezze e larghezze di petali e sepali di iris, per riconoscere il tipo di iris a partire da queste misure:
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
## 4 4.6 3.1 1.5 0.2 setosa
## 5 5.0 3.6 1.4 0.2 setosa
## 6 5.4 3.9 1.7 0.4 setosa## 'data.frame': 150 obs. of 5 variables:
## $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ...
## $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ...
## $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ...
## $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ...
## $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 ..2.1 Grafici di serie storiche
Supponendo che i dati siano raccolti in sequenza temporale, questa sequenza deve essere in qualche modo evidenziata nei grafici. Per poter fare un esempio con i dati degli iris, supponiamo quindi che a ciascuna misurazione sia associata una data/ora di rielvazione; creeremo quindi una nuova variabile che “simula” questo fatto e vedremo alcune semplici rappresentazioni grafiche per descrivere i dati:
# Crea una nuova variabile con data/ora che contiene valori che iniziano
# con alle "2012-10-10 08:00:00" e proseguono con incrementi di 1 minuto
iris$datetime <- seq.POSIXt(from = as.POSIXct("2012-10-10 08:00:00"),
by = "1 min", length.out = nrow(iris))
# Aggiunge una colonna labels che assume i valori di Sepal.Length
# solo quando Sepal.Width < 2.8 o Sepal.Width > 3.3
iris$labels <- ifelse(iris$Sepal.Width < 2.8 | iris$Sepal.Width > 3.3,
as.character(iris$Sepal.Length), "")
# Genera il grafico con ggplot
ggp <- ggplot(data = iris, aes(x = datetime, y = Sepal.Length)) +
# Traccia i punti dei valori con colori che dipendono da Sepal.Length
geom_point(aes(colour = Sepal.Length))+
# Traccia la linea blu che unisce i valori
geom_line(col = "blue") +
# Il titolo generale del grafico
ggtitle("Grafico di serie storica per Sepal.Length") +
# I nomi degli assi x e y
xlab("Data/ora") + ylab("Sepal Length") +
# Aggiunge dei valori di testo contenuti nella colonna "labels"
geom_text(aes(label = labels))
# stampa (mostra) il grafico risultante
print(ggp)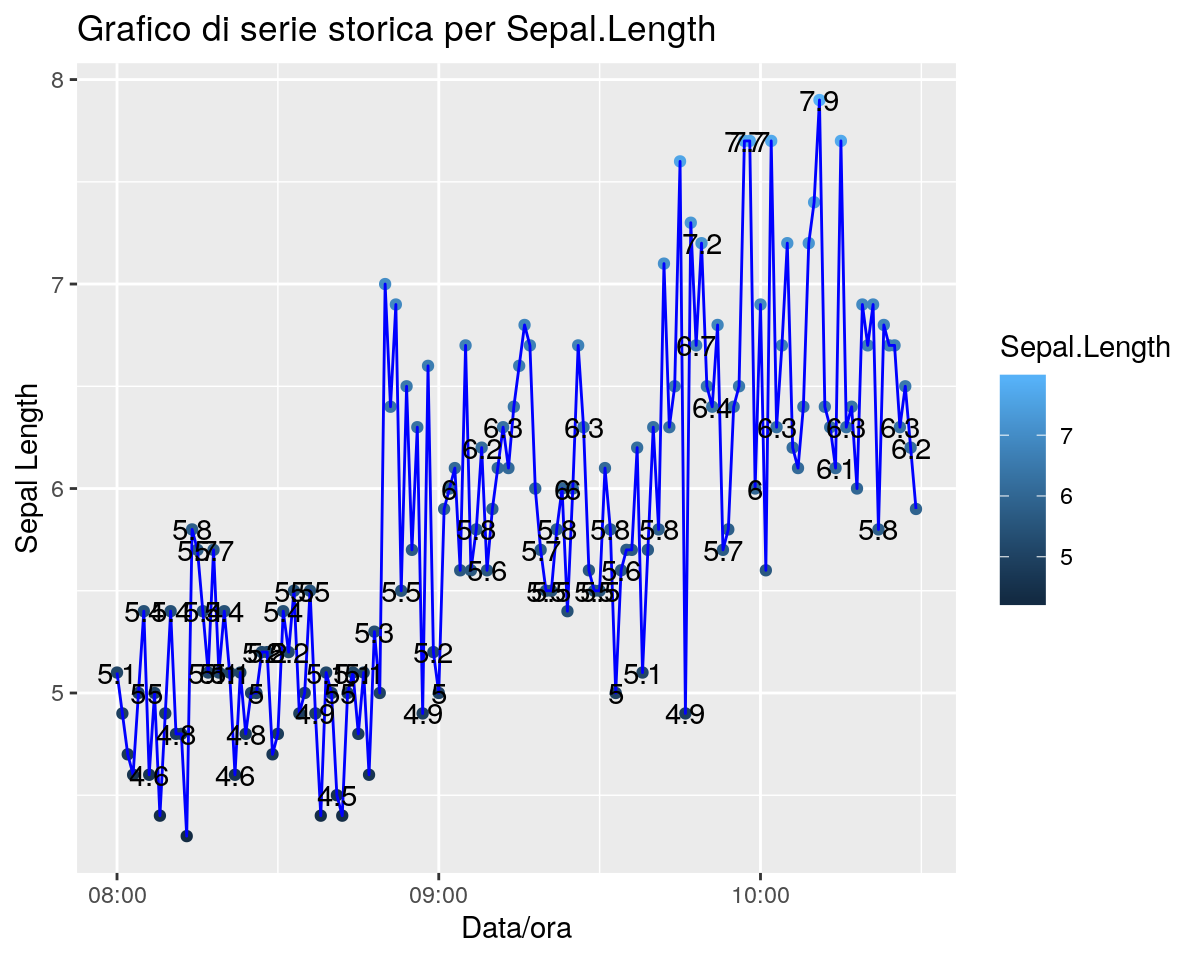
Per tracciare più linee in un solo grafico, ci sono diverse alternative.
In questo esempio si traccia una linea per Sepal.Length e una linea per Sepal.Width creando un nuovo data frame con i valori delle due variabili in una sola colonna, una colonna con data/ora, e una colonna che indica la misura presente nella singola riga:
# Prepara i dati per fare il grafico
dt <- data.frame(measure = c(iris$Sepal.Length,iris$Sepal.Width),
type = c(rep("Sepal Lentgh",150), rep("Sepal Width",150)),
datetime=rep(iris$datetime,2))
# Si genera il grafico: il parametro colour permette di fare una linea
# con colore diverso per i due tipi (type) di iris
ggp <- ggplot(data = dt, aes(x = datetime, y = measure, colour = type)) +
geom_line() +
ggtitle("Grafico di serie storica per Sepal.Length e Sepal.Width") +
xlab("Data/ora") + ylab("Misure")
print(ggp)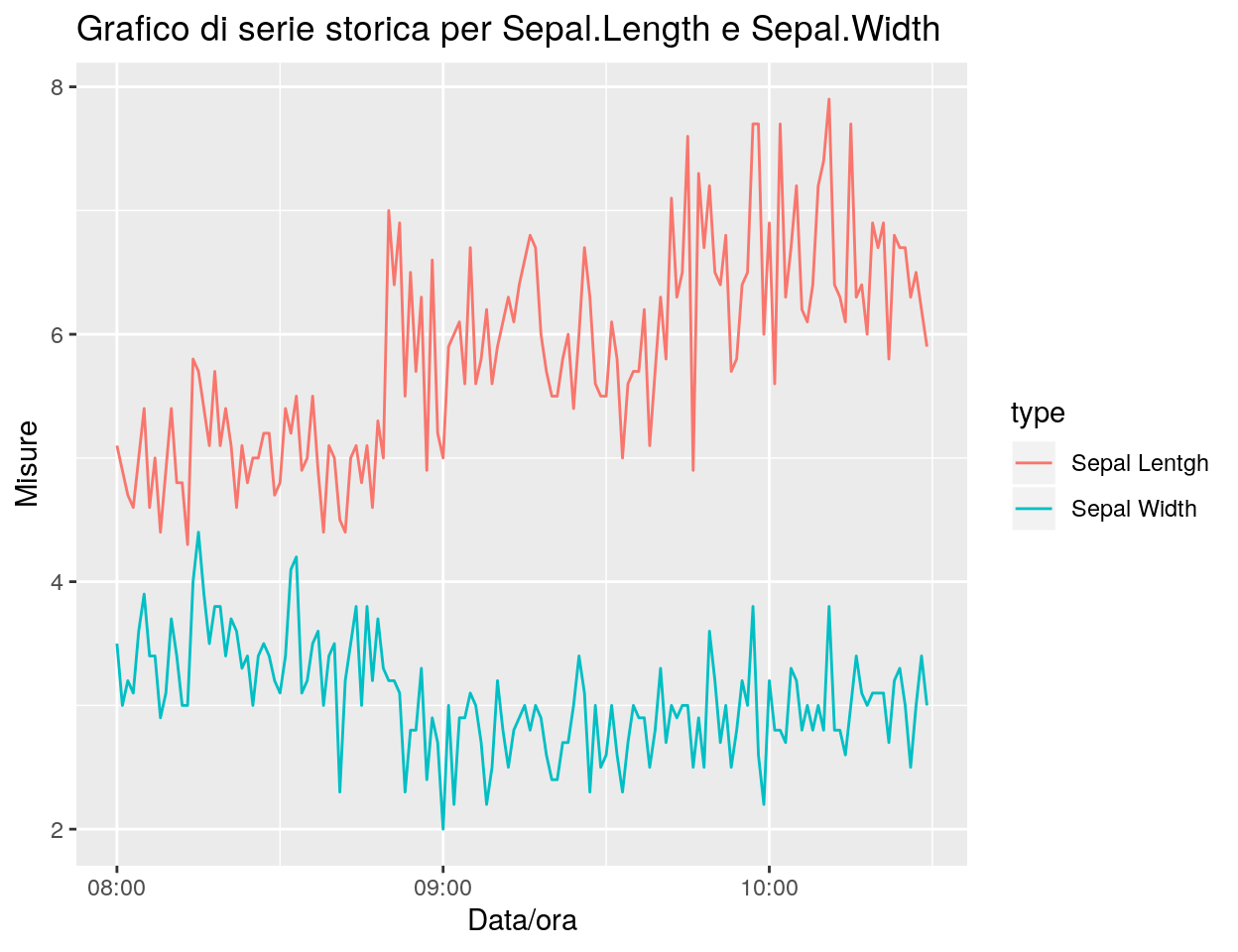
In questo esempio invece si tracciano separatamente le linee per Sepal.Length e Sepal.Width. Si noti come in questo caso non sia automaticamente mostrata la legenda.
ggp <- ggplot(data = iris, aes(x = datetime, y = Sepal.Length)) +
# Traccia la linea blu per Sepal.Length
geom_line(colour = "blue") +
# Traccia la linea rossa per Sepal.Width
geom_line(aes(y = Sepal.Width), colour = "red") +
ggtitle("Grafico di serie storica per Sepal.Length e Sepal.Width") +
xlab("Data/ora") + ylab("Misure")
print(ggp)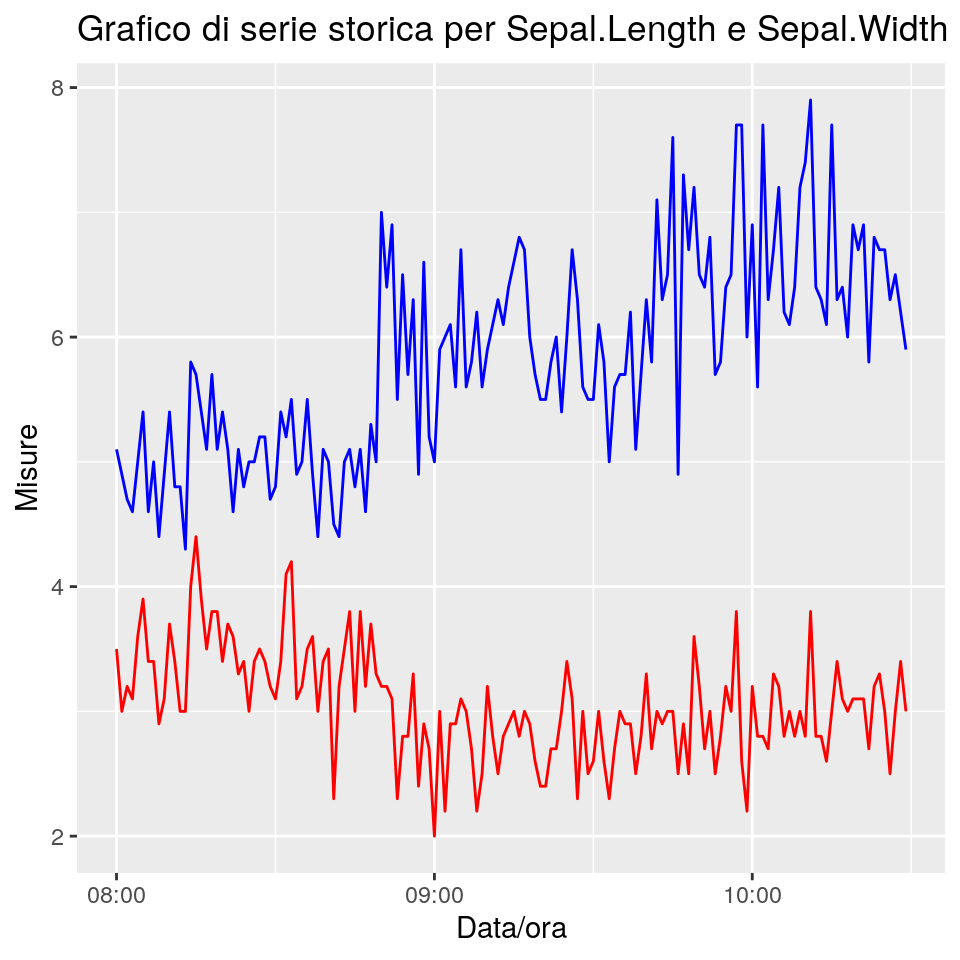
2.2 Istogrammi
Il codice che segue produce un istogramma per la variabile Sepal.Length. Se osservate il comando di assegnazione qui sotto, composto da due righe, è racchiuso tra parentesi tonde. Racchiudere un comando tra parentesi tonde significa “fai il print di quanto ottenuto”. In questo caso si ottiene un oggetto di tipo ggplot, che una volta assegnato alla variabile ggp, viene immediatamente visualizzato.
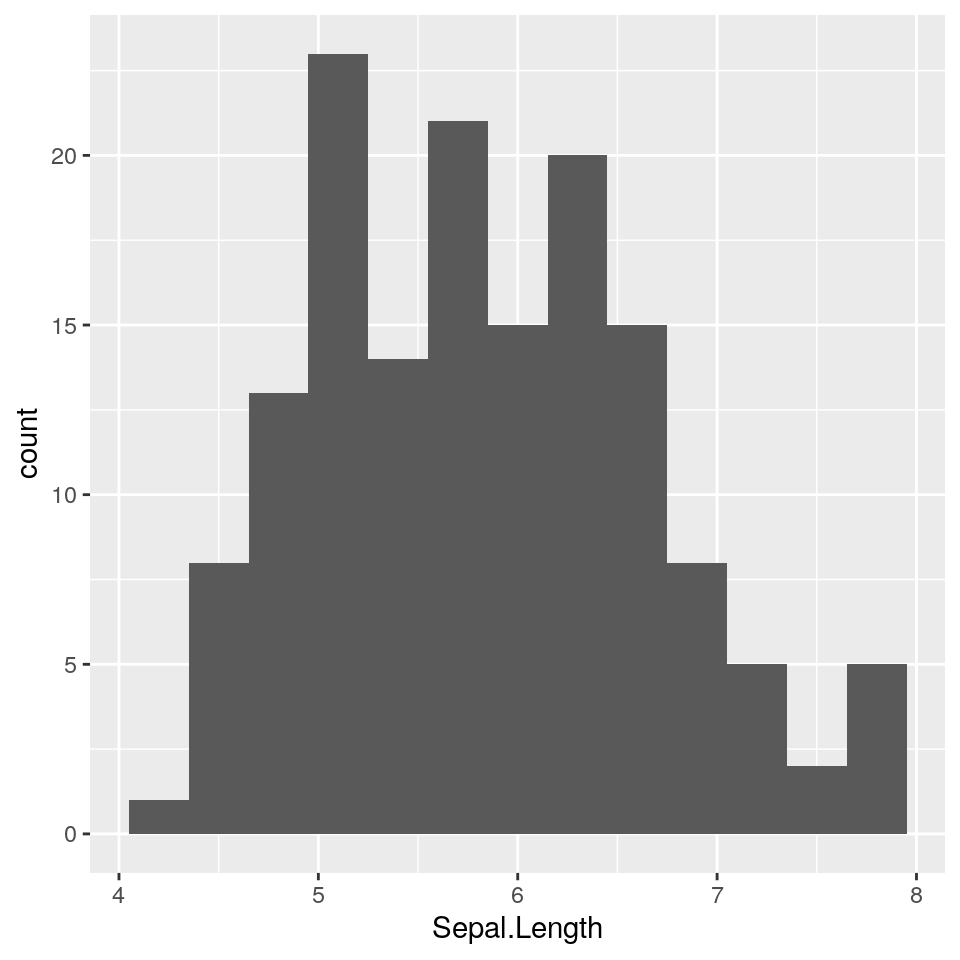
In questo caso tracciamo le barre dell’istogramma usando bordi neri e riempimento bianco:
(ggp <- ggplot(iris, aes(x = Sepal.Length)) +
geom_histogram(binwidth = .3, colour = "black", fill = "white"))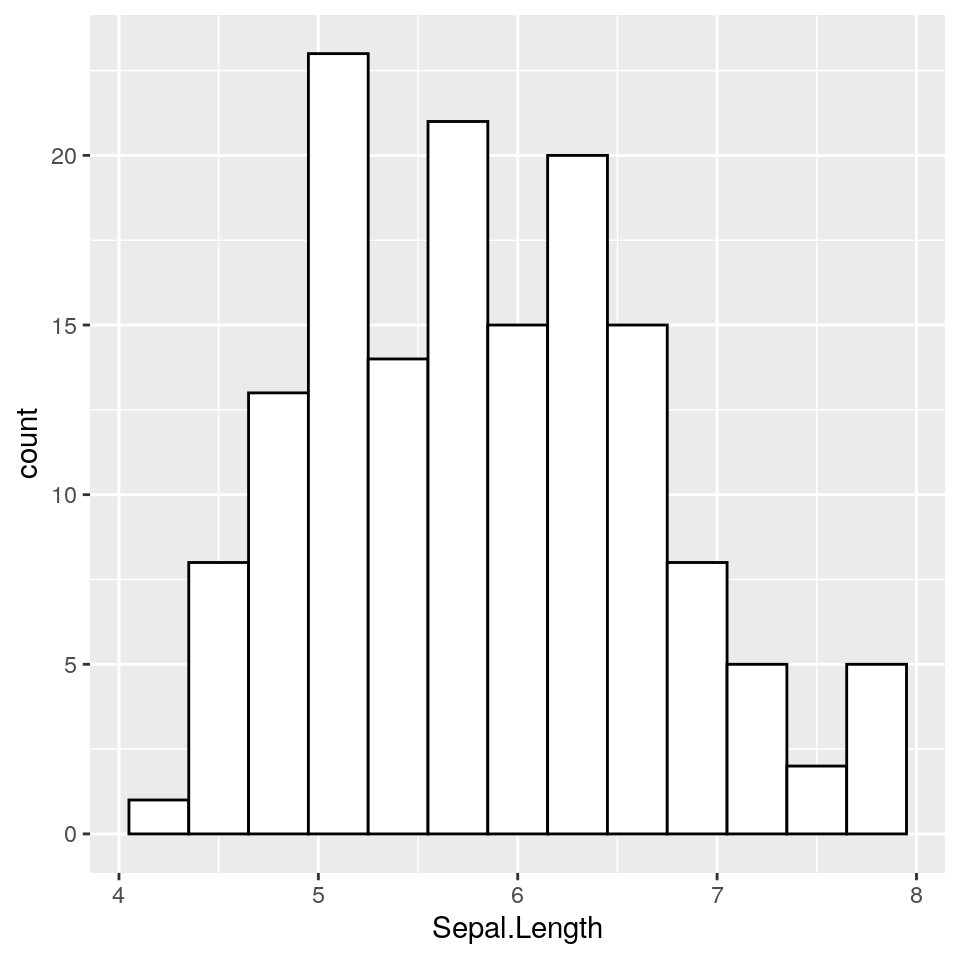
In questo caso invece tracciamo una stima della densità:
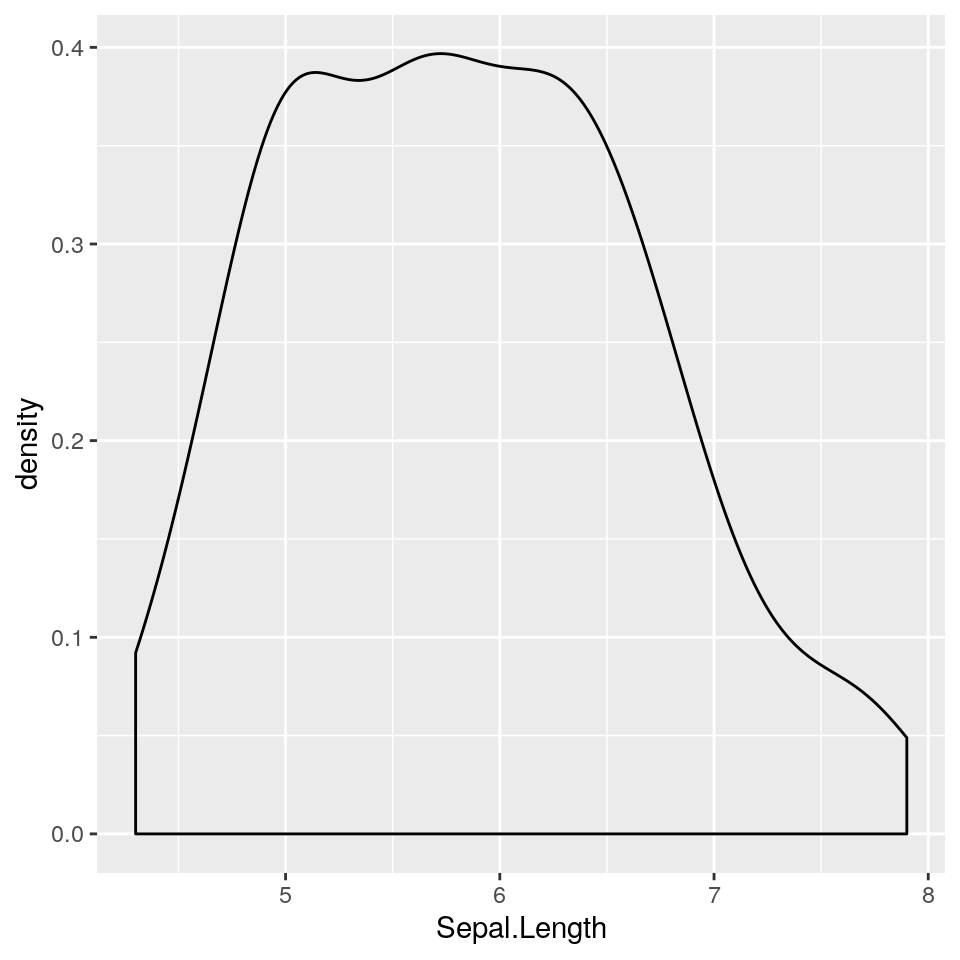
Si possono ovviamente unire le due cose, creando un istogramma con curva di densità stimata. In questo caso, per poter avere una scala comune con la densità le barre dell’istogramma non devono mostrare i conteggi assoluti ma il valore di densità: a grandi linee le frequenze relative.
ggp <- ggplot(iris, aes(x = Sepal.Length)) +
# L'istogramma mostra la densità invece che i conteggi sull'asse y
geom_histogram(aes(y = ..density..),
binwidth = .3, colour = "black", fill = "white") +
# La densità è sovraimpressa con una trasparenza (alpha = 0.2)
geom_density(alpha = .2, fill = "#FF6666")
print(ggp)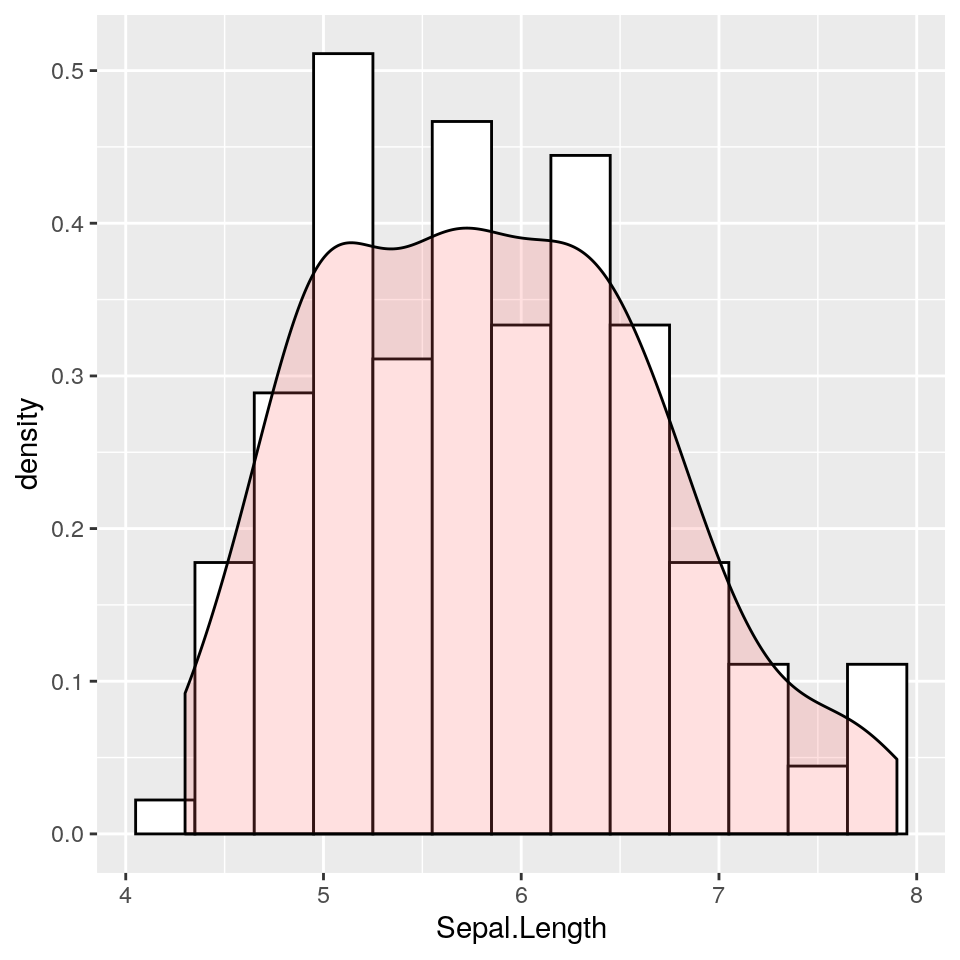
Un altro esempio in cui al grafico precedente vengono aggiunte le barre colorate in base ai valori di densità:
ggp <- ggplot(iris, aes(x = Sepal.Length)) +
geom_histogram(aes(y = ..density.., fill = ..density..),
binwidth = .3, colour = "black") +
geom_density(alpha = .2, fill = "#FF6666")
print(ggp)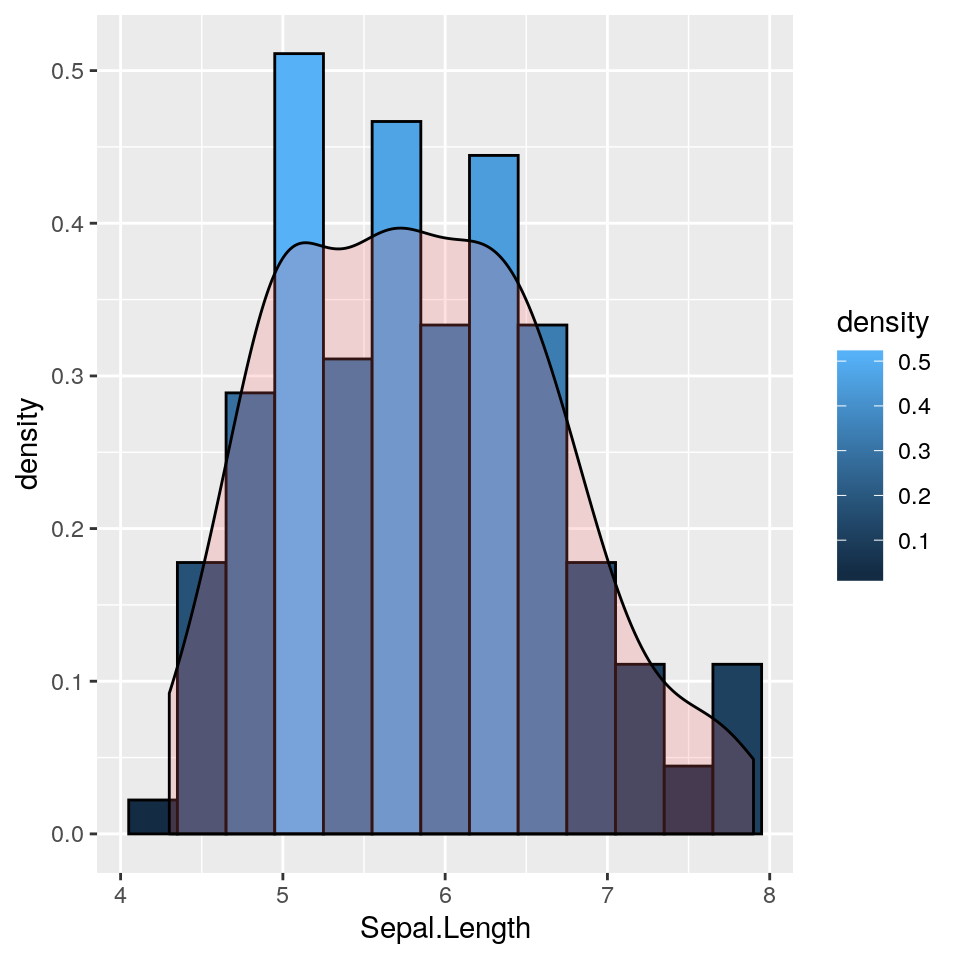
In questo caso, invece, all’istogramma “classico” di Sepal.Length è aggiunta una linea verticale tratteggiata in corrispondenza del valore medio di Sepal.Length stesso:
ggp <- ggplot(iris, aes(x = Sepal.Length)) +
geom_histogram(binwidth = .5, colour = "black", fill = "white") +
geom_vline(aes(xintercept = mean(Sepal.Length, na.rm = TRUE)),
color = "red", linetype = "dashed", size = 1)
print(ggp)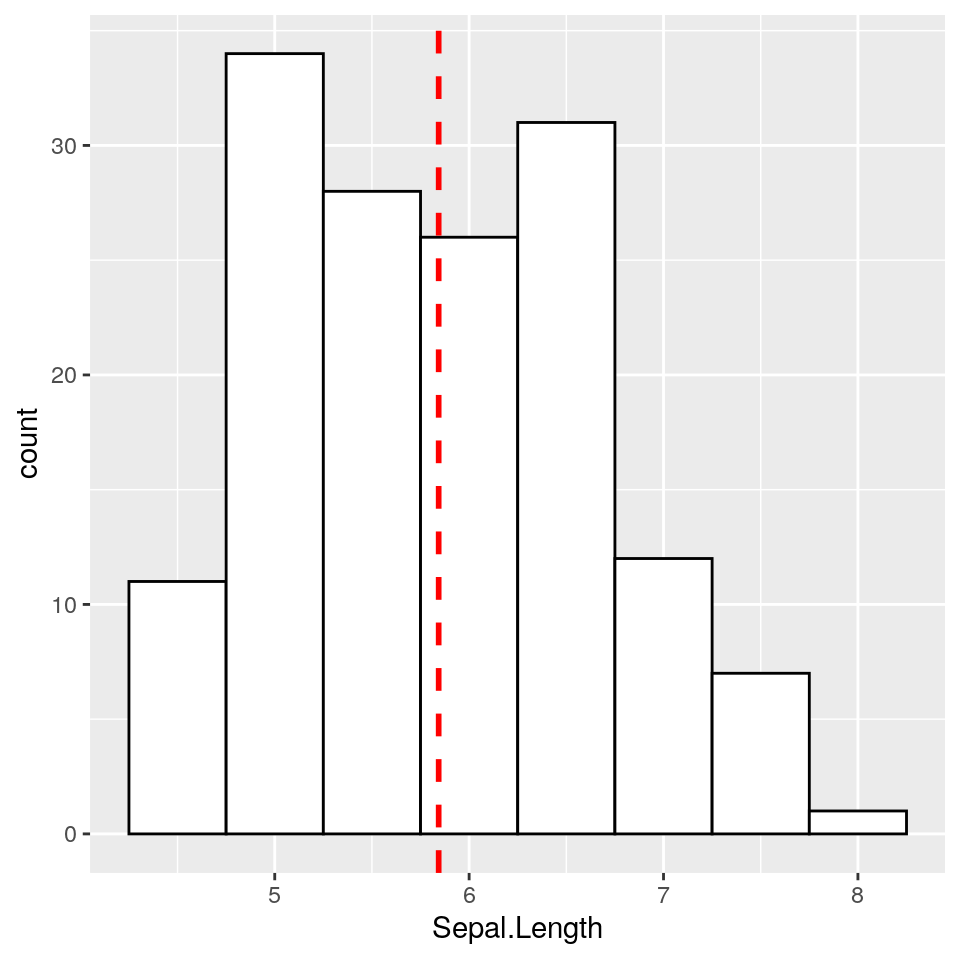
Un grafico un po’ più di impatto, dove si mettono a confronto le densità di due variabili (in questo caso Sepal.Length e Sepal.Width):
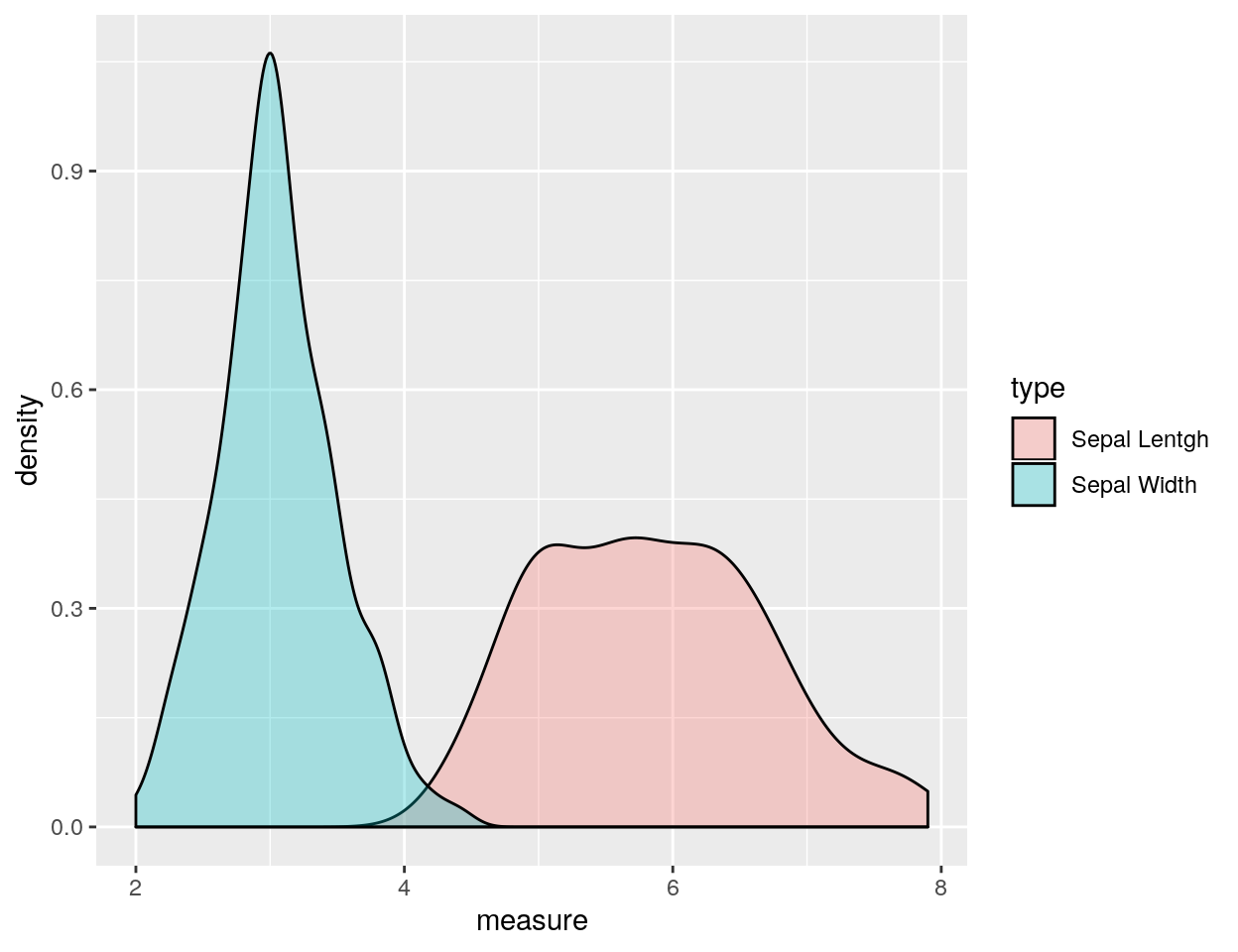
Nell’esempio che segue, invece, sono tracciati gli istogrammi invece delle densità
(ggp <- ggplot(dt, aes(x = measure, fill = type)) +
# position="identity" usato per non avere istogrammi impilati
# (default in questo caso)
geom_histogram(alpha = 0.3, position = "identity")) 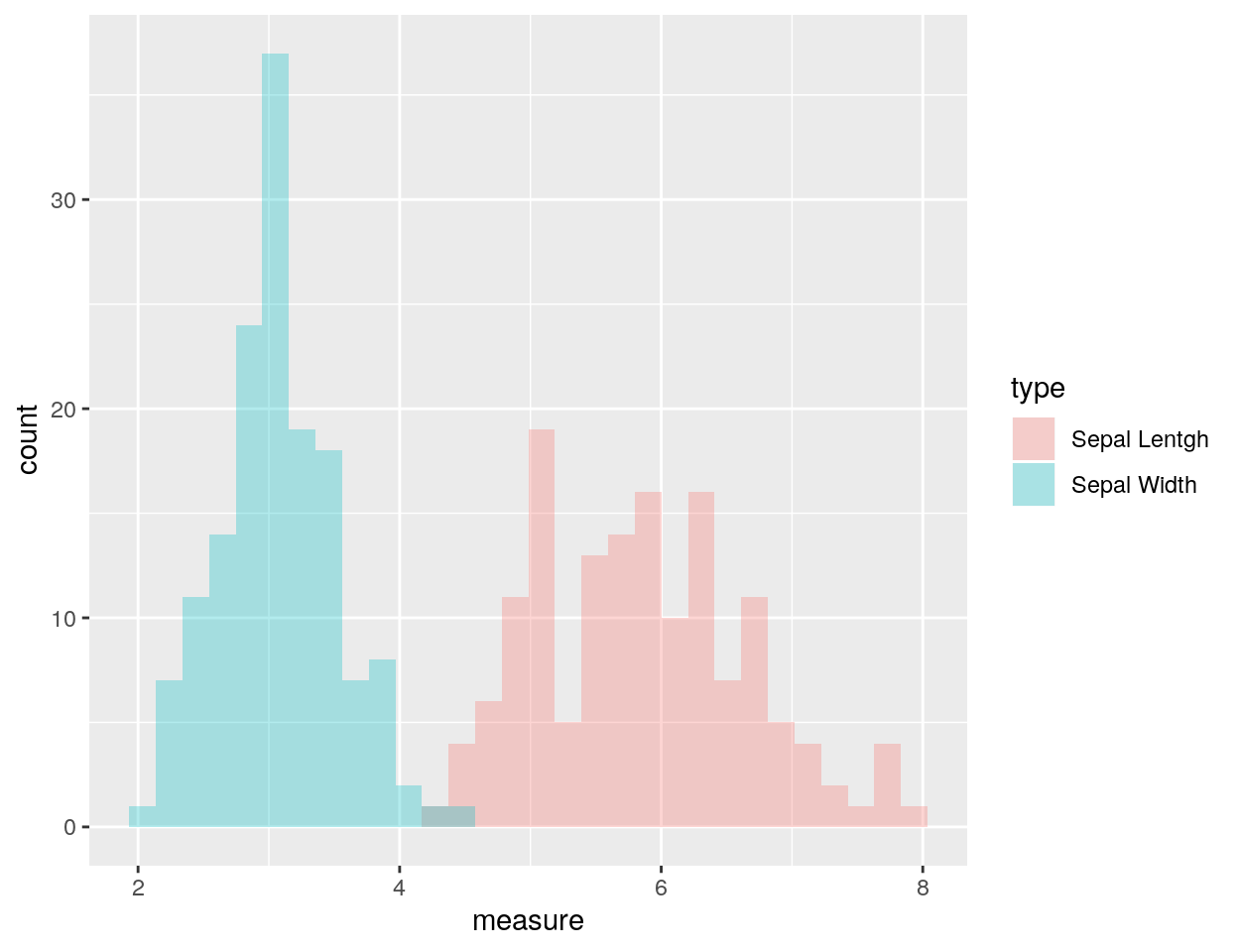
2.3 Boxplot
I boxplot (o grafici box-and-whiskers) in ggplot sono “mutivariati” per costruzione, essendo finalizzati principalmente a confrontare distribuzioni di sottoinsiemi diversi di dati. Per questa ragione, il parametro x di geom_boxplot() richiede il nome della variabile di raggruppamento e il parametro y richiede il nome della variabile contenente le misure nel dataframe considerato. Se si vuole generae il boxplot di una sola variabile, si vede specificare x = "".
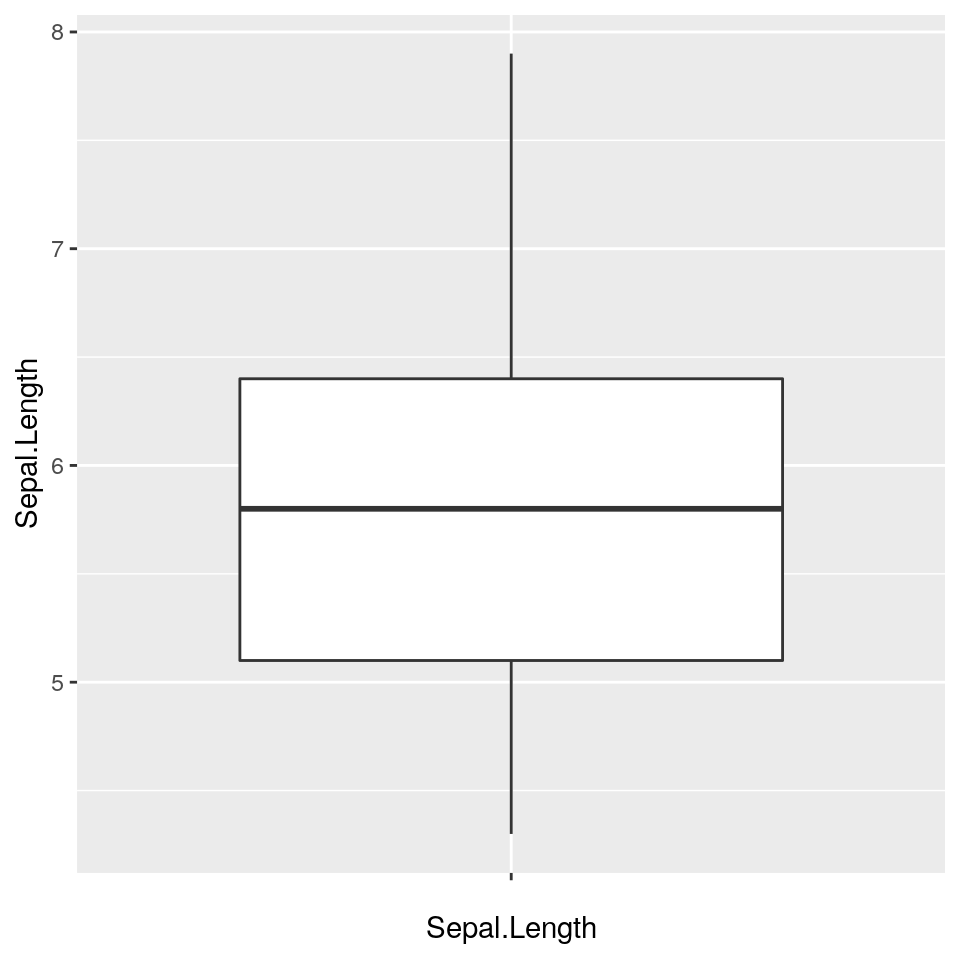
Se si vogliono mostrare i boxplot orizzontali, basta usare coord_flip(). Questa funzione, applicabile a tutti i tipi di grafico di ggplot2, permette di invertire i due assi.
Ora vediamo un paio di boxplot “standard”. Il secondo crea un sottografico diverso per ciascuna specie, grazie alla funzione facet_grid():
ggp <- ggplot(iris, aes(x = Species, y = Sepal.Length)) +
geom_boxplot() +
ggtitle("Sepal Length Vs Tipo di Iris")
print(ggp)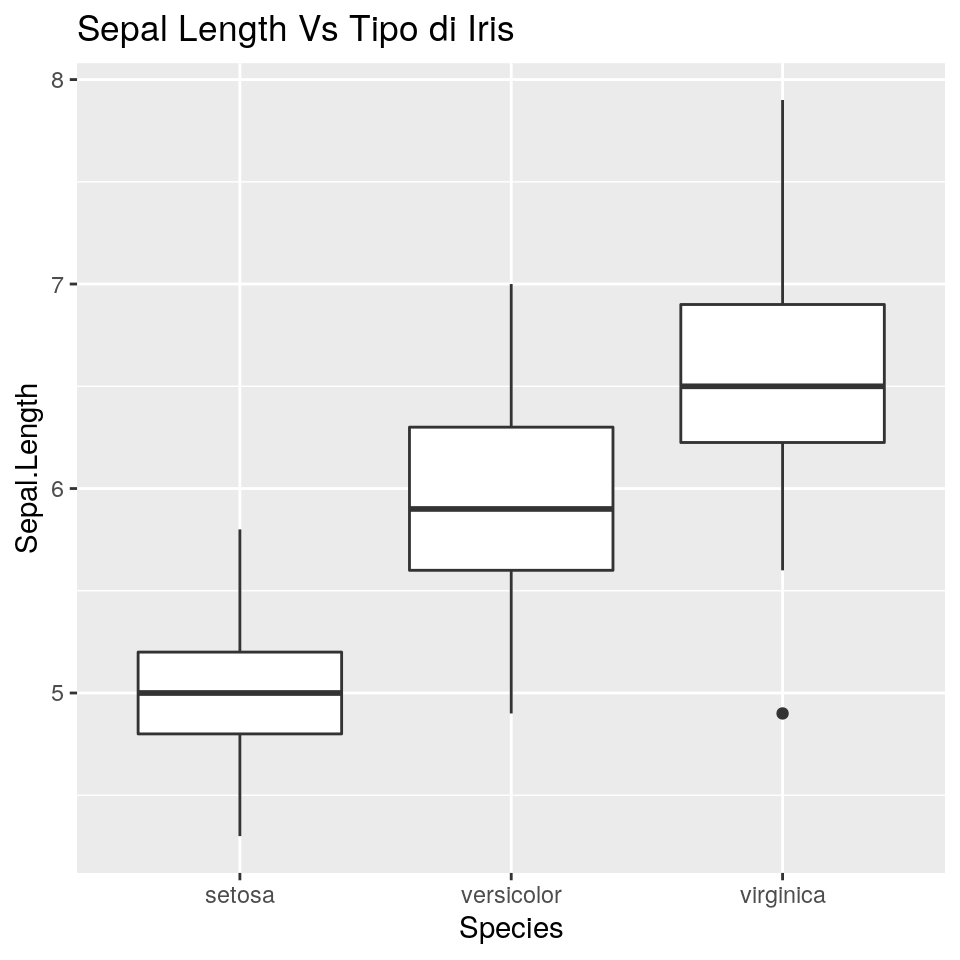
ggp <- ggplot(iris, aes(x = "", y = Sepal.Length)) +
geom_boxplot() +
facet_grid(facets = ~Species, as.table = TRUE)
print(ggp)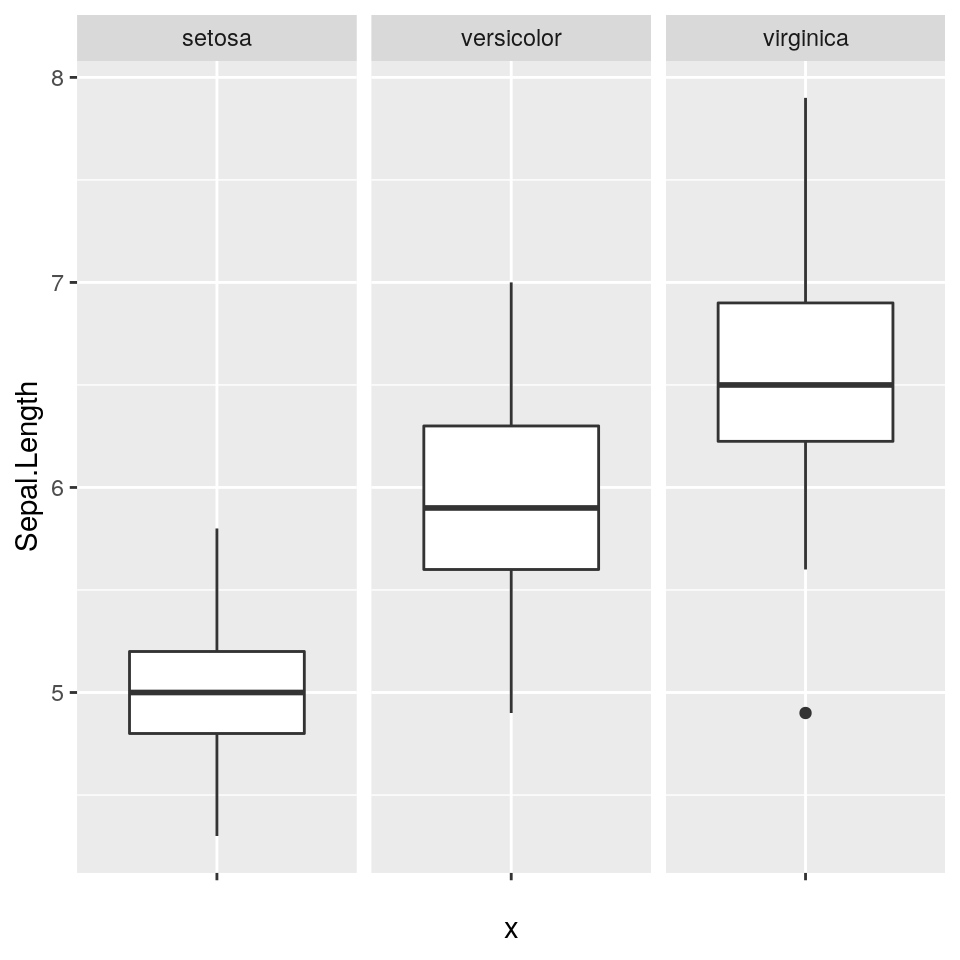
2.4 Grafici a violino (Violin plot)
I violin plot sono simili ai boxplot; la principale differenza è che i grafici a violino mostrano la distribuzione della variabile invece che “riassunti”. Anche i violin plot in ggplot sono di natura “multivariata”.
ggp <- ggplot(iris, aes(x = "", y = Sepal.Length)) +
geom_violin() +
xlab("Sepal.Length")
print(ggp)
E’ possibile anche aggiungere un ulteriore “strato” in cui sono mostrati i singoli punti sovraimpessi al violino:
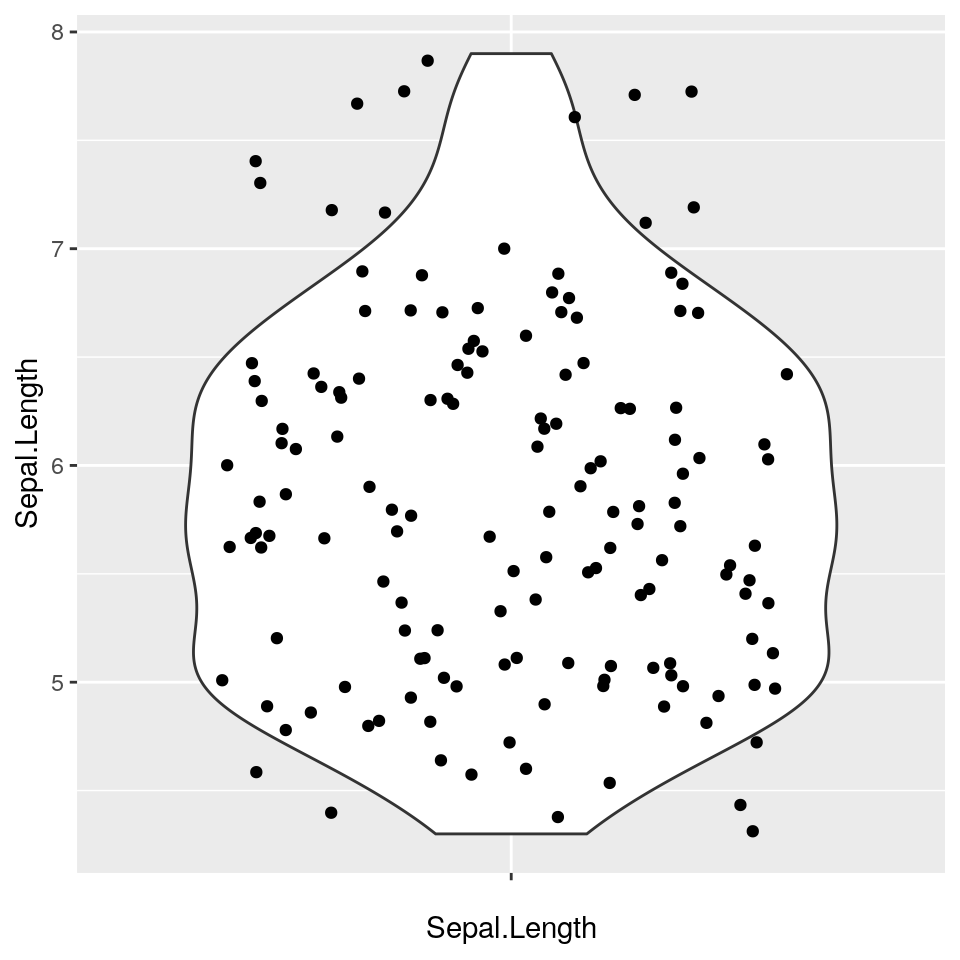
Un violin plot “standard”:
ggp <- ggplot(iris, aes(x = Species, y = Sepal.Length)) +
geom_violin() +
ggtitle("Sepal Length Vs Tipo di Iris")
print(ggp)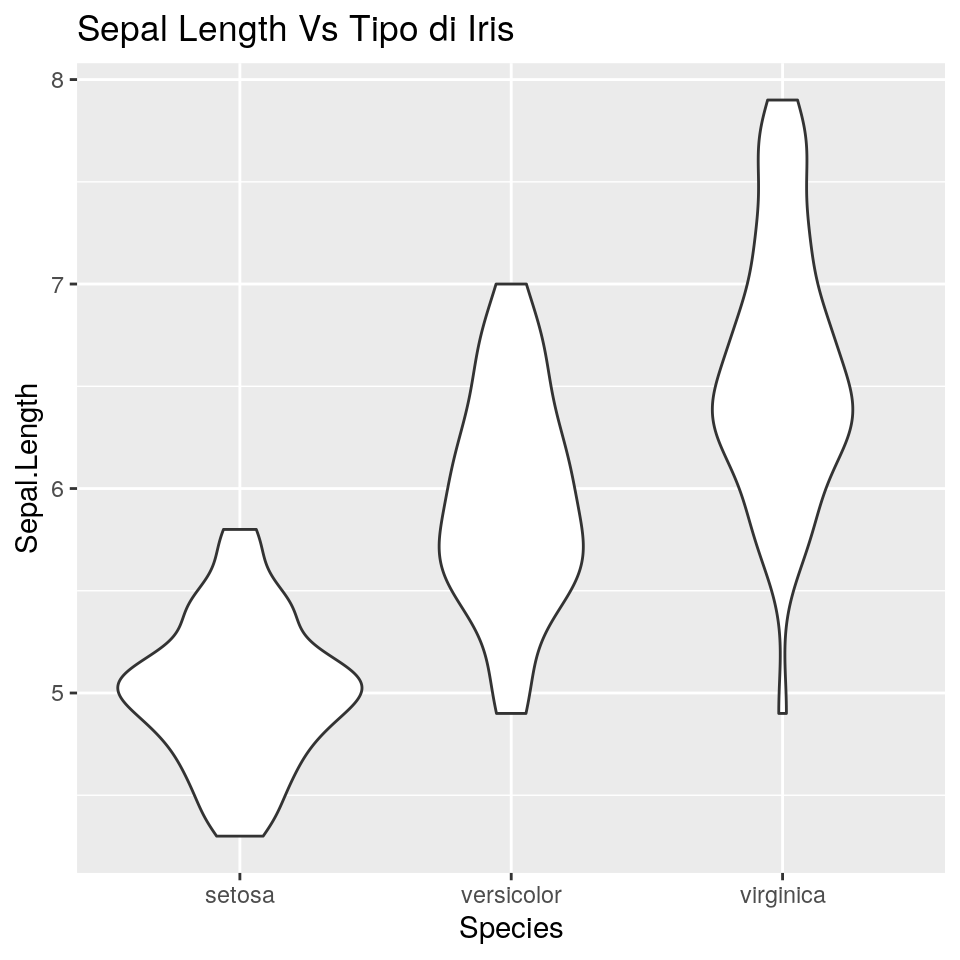
Sovraimponiamo anche il boxplot:
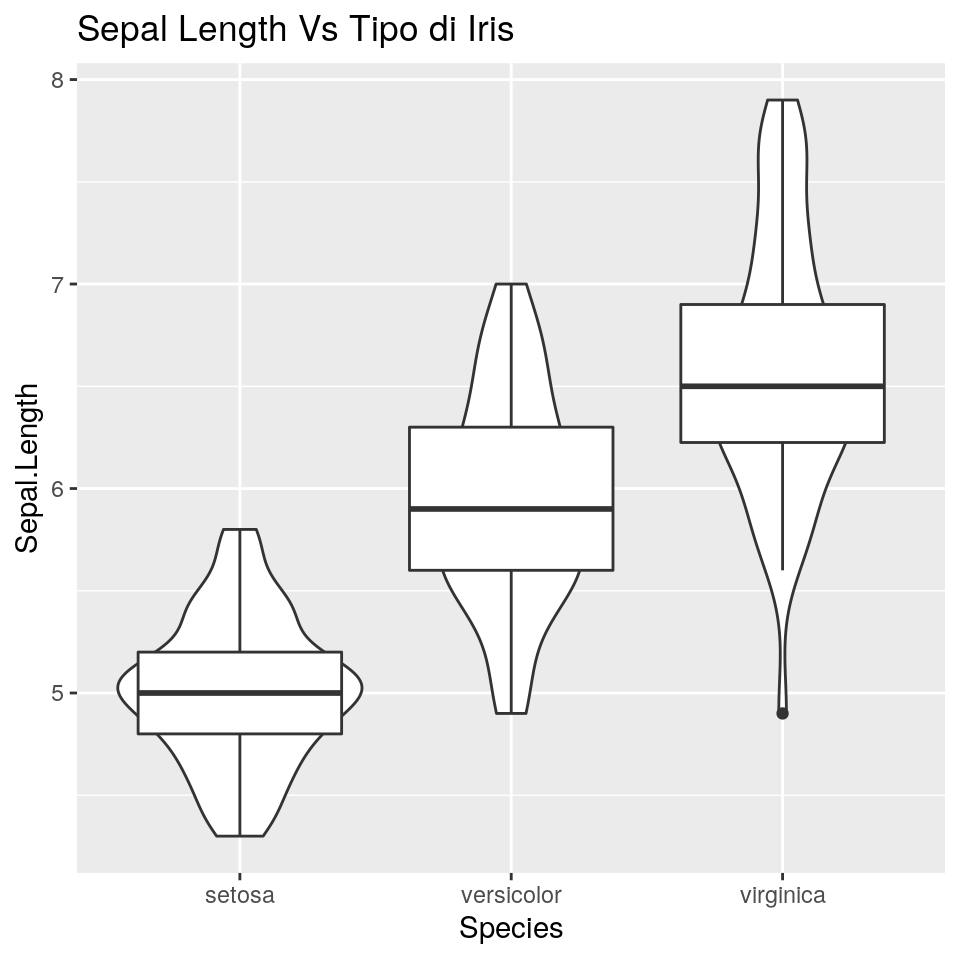
E quindi i punti:
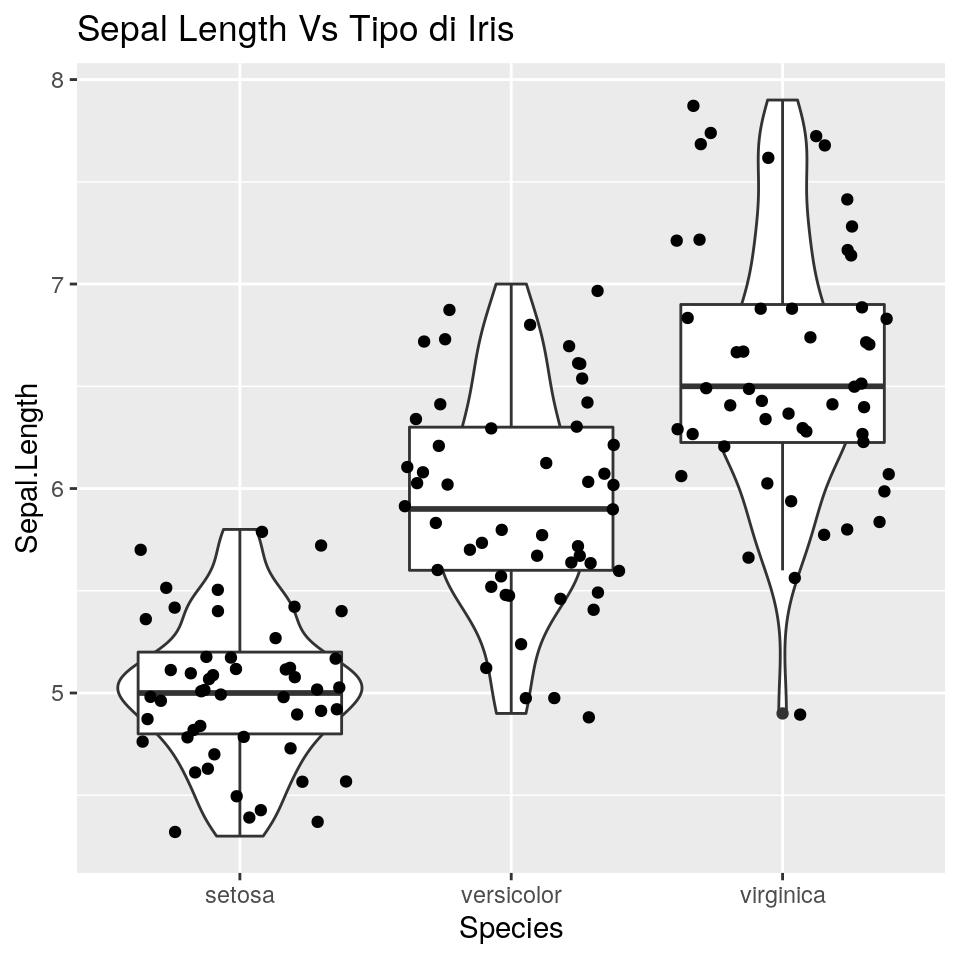
I boxplot possono anche essere usati per identificare potenziali outlier.
Per ilustrare questa possibilità dei boxplot useremo il dataset forbes94:
## Classes 'tbl_df', 'tbl' and 'data.frame': 800 obs. of 30 variables:
## $ TotalComp : int 600300 1487600 1508180 4069420 1088150 1099010 1652560 7..
## $ WideIndustry : Factor w/ 19 levels "Aerospacedefense",..: 1 1 1 1 1 1 1 1 1 ..
## $ Company : Factor w/ 800 levels "20th Century Industr",..: 694 103 526 4..
## $ CEO : Factor w/ 796 levels "Dr. Andrew S Grove",..: 777 221 453 530..
## $ CityofBirth : Factor w/ 402 levels "","Aberdeen",..: 288 35 250 94 18 76 13..
## $ StateofBirth : Factor w/ 51 levels "","AK","AL","AR",..: 40 15 36 7 22 37 40..
## $ Age : int 52 62 56 58 56 60 62 58 59 64 ...
## $ Undergrad : Factor w/ 262 levels "","Albion C",..: 83 186 106 124 124 67 ..
## $ UGDegree : Factor w/ 25 levels "","AAS","AB",..: 13 23 13 17 13 3 19 13 ..
## $ UGDate : int 63 54 59 57 60 55 54 57 56 52 ...
## $ AgeOfUnder : int 21 22 21 21 22 21 22 21 21 22 ...
## $ Graduate : Factor w/ 129 levels "","American Grad S",..: 22 27 39 50 50 ..
## $ GradDegree : Factor w/ 20 levels "AM","EdD","JD",..: 12 8 12 15 12 8 16 20..
## $ MBA : int 0 1 0 0 0 1 0 0 0 0 ...
## $ MasterPhd : int 1 1 1 1 1 1 1 1 1 1 ...
## $ G_date : int 67 58 61 59 62 57 55 60 58 53 ...
## $ AgeOfGradu : int 25 26 23 23 24 23 23 24 23 23 ...
## $ YearsFirm : int 8 36 19 17 32 10 39 34 4 13 ...
## $ YearsCEO : int 3 8 4 6 6 9 5 13 2 1 ...
## $ Salary : int 600000 796935 675000 830000 559477 650833 762500 1750000..
## $ Bonus : int NA 624000 450000 800000 495100 330000 650000 2200000 950..
## $ Other : int 300 66669 383184 1645320 33569 118175 240064 441046 5964..
## $ StGains : int NA NA NA 794103 NA NA NA 2894380 NA NA ...
## $ Compfor5Yrs : int 2560750 7857540 7719720 12625100 4452230 4803290 6614390..
## $ StockOwned : num 0.004 0.004 0.576 0.108 3.326 ...
## $ Sales : int 2492 25438 5063 9436 14487 1905 13071 60562 9078 3187 ...
## $ Profits : num 72.8 1244 96 450.3 396 ...
## $ ReturnOver5Yrs: int -9 10 13 17 7 1 11 21 19 24 ...
## $ Industry : Factor w/ 71 levels "Aerospacedefense",..: 1 1 1 1 1 1 1 1 1 ..
## $ IndustryCode : num 11 11 11 11 11 11 11 11 11 11 ...E ora rappresentiamo la distribuzione dei salari per settore economico:
ggp <- ggplot(forbes94, aes(x = WideIndustry, y = Salary)) +
geom_boxplot(outlier.shape = 19, outlier.colour = "red", outlier.size = 2) +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
ggtitle("Salario vs. Settore economico")
print(ggp)## Warning: Removed 11 rows containing non-finite values (stat_boxplot).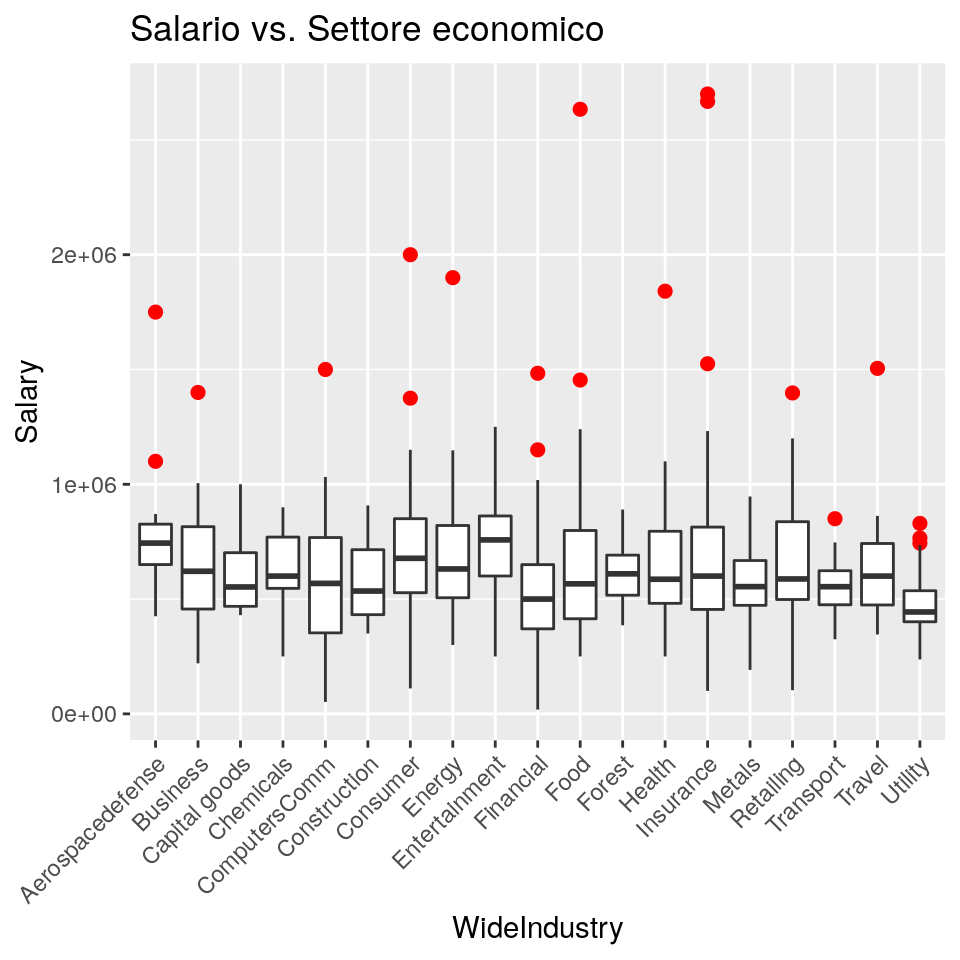
I boxplot qui sopra permettono di confrontare le distribuzioni dei salari dei principali settori economici.
Per esempio, il grafico permette di dire che nel settore della difesa aereospaziale (Aerospace defense) i redditi sono mediamente più
elevati e meno variabili che nella gran parte degli altri settori. Oltre a ciò,
mostrano chiaramente che in alcune industrie ci sono alcuni valori anomali. Questi sono evidenziati in ciascun
boxplot come osservazioni isolate, in rosso (outlier.colour = "red"). Gli outlier, in qualità di punti anomali,
spesso richiedono una analisi specifica per comprenderne le caratteristiche e l’origine. Personalmente NON RITENGO IN GENERALE CORRETTO
rimuovere gli outlier senza alcuno studio (ma su questo aspetto sono aperto a confronti).
2.5 Grafici 2D
Il tipo rappresentazione grafica 2D più comune e intuitivo è probabilmente lo “scatterplot” o “diagramma a dispersione”.
Nei paragrafi che seguono, cercheremo di presentare alcuni esempi di rappresentazioni con scatterplot di ggplot.
2.5.1 Scatterplot semplice
Nel grafico che segue viene mostrata la relazione esistente tra i valori di Sepal.Length e Sepal.Width senza distinzioni tra le le specie di iris:
ggp <- ggplot(iris, aes(x = Sepal.Length, y=Sepal.Width)) +
geom_point() +
ggtitle("Sepal Width Vs. Sepal Length")
print(ggp)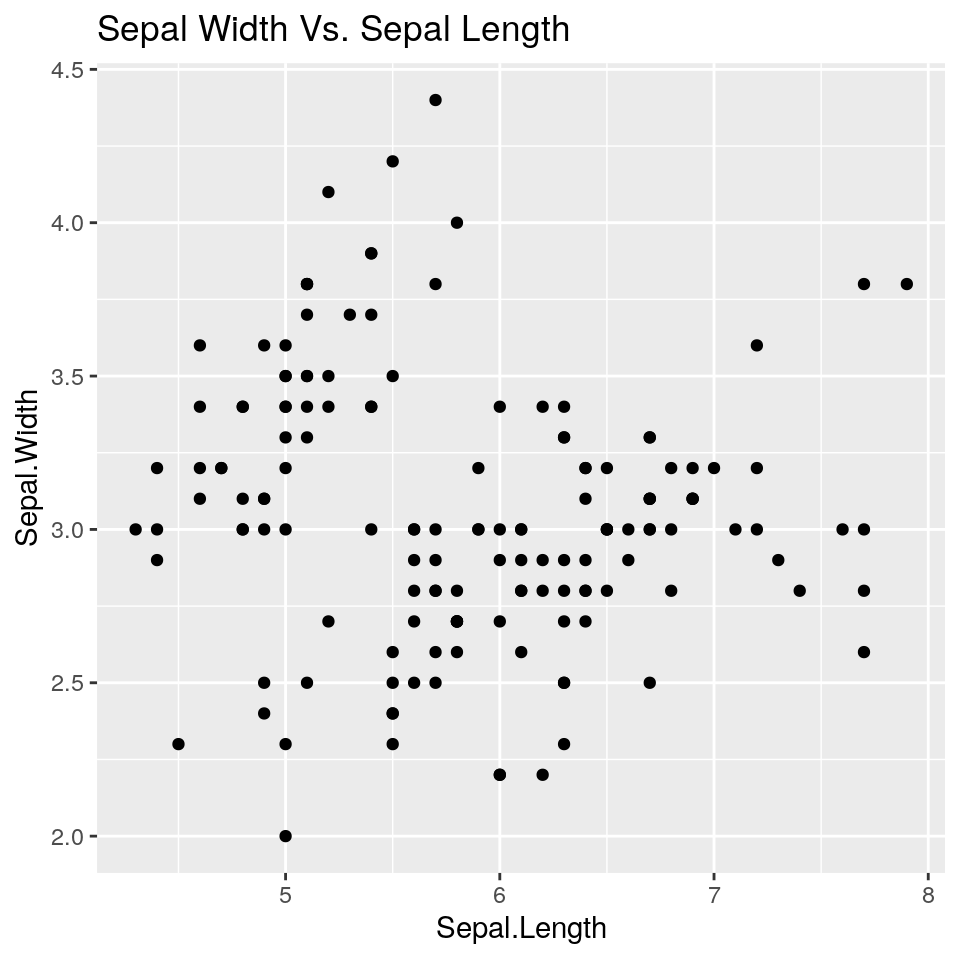
E’ chiaro che non siamo in grado, a partire da questo grafico, di comprendere se tipi di iris diversi creano raggruppamenti diversi di punti o se i tipi di
iris non si differenziano rispetto a Sepal.Length e Sepal.Width.
Per questa ragione proveremo a migliorare la rappresentazione con gli scatterplot categorizzati.
2.5.2 Scatterplot categorizzato (tramite colori)
E’ possibile distinguere i diversi tipi di iris evidennziandoli con colori diversi.
ggp <- ggplot(iris, aes(x = Sepal.Length, y=Sepal.Width)) +
geom_point(mapping = aes(colour=Species)) +
ggtitle("Sepal Width Vs. Sepal Length per Specie")
print(ggp)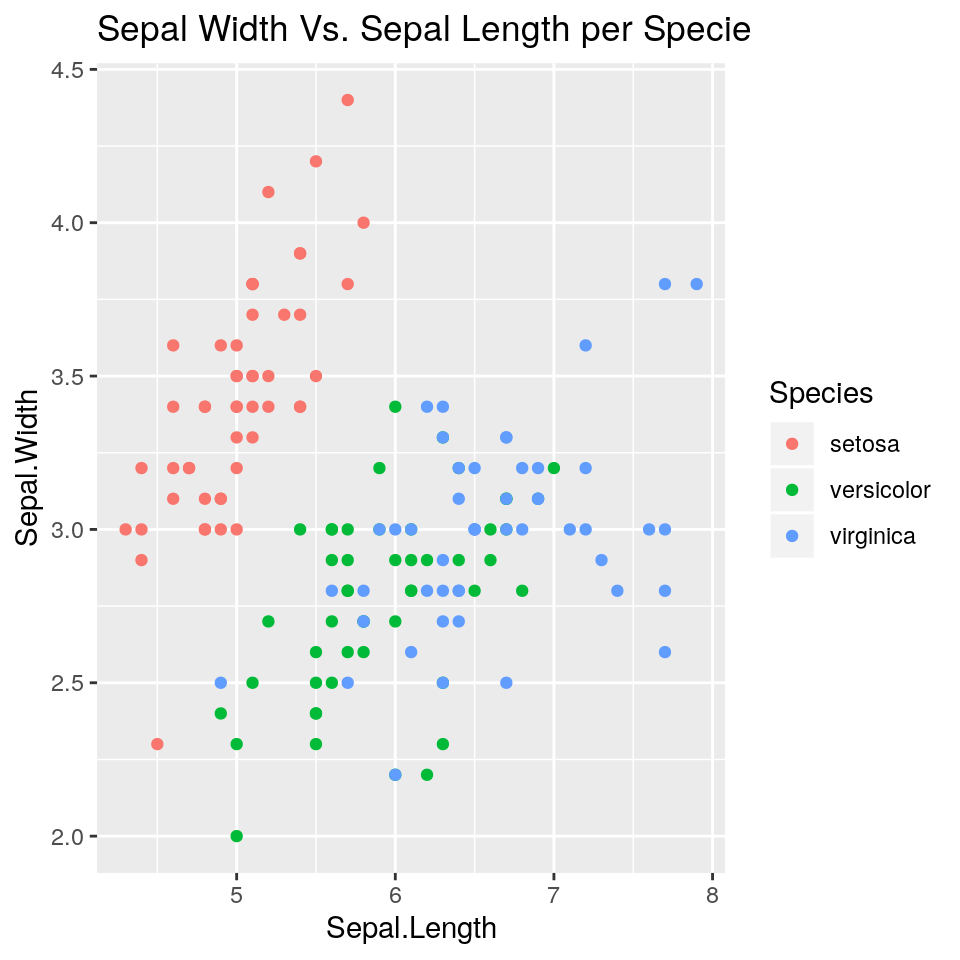
Da questo grafico si comprende che i tre tipi di iris si distribuiscano in aree anche molto diverse dei valori diSepal.Length e Sepal.Width; per esempio, gli iris di tipo Setosa si posizionano in un’area molto diversa rispetto agli altri due.
2.5.3 Scatterplot categorizzato (tramite colori e simboli)
E’ possibile distinguere i diversi tipi di iris evidenziandoli con colori diversi, ma anche con simboli diversi.
Questa scelta può essere utile quando si fanno grafici che dovranno essere stampati per una pubblicazione in bianco e nero, per esempio un articolo di una rivista scientifica.
ggp <- ggplot(iris, aes(x = Sepal.Length, y=Sepal.Width)) +
geom_point(mapping = aes(colour=Species, shape=Species)) +
ggtitle("Sepal Width Vs. Sepal Length")
print(ggp)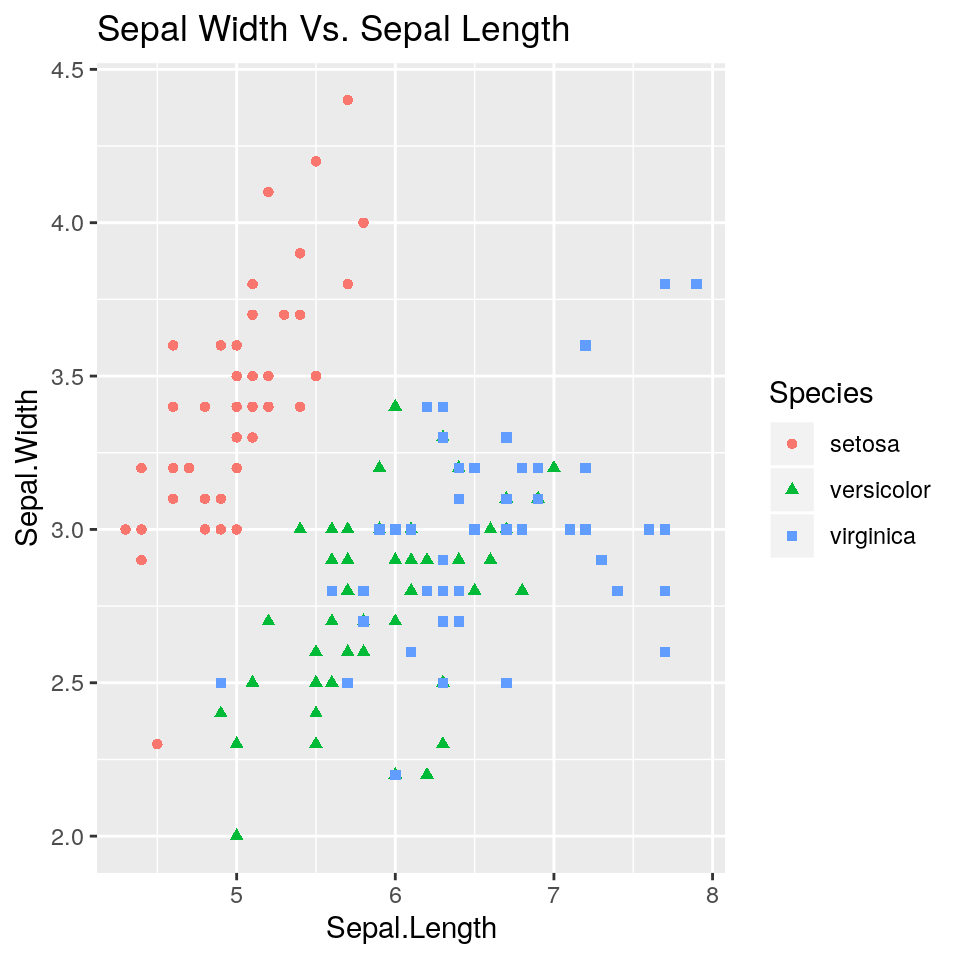
2.6 Grafici 3D
Se si desidera tracciare dei grafici in 3D, ci sono diverse opzioni disponibili.
Proviamo a vedere un esempio con il dataset volcano3d, cominciando dalle opzioni offerte da ggplot2.
2.6.1 Grafici a linee di livello
## # A tibble: 6 x 3
## x y z
## <int> <int> <dbl>
## 1 1 1 100
## 2 2 1 101
## 3 3 1 102
## 4 4 1 103
## 5 5 1 104
## 6 6 1 105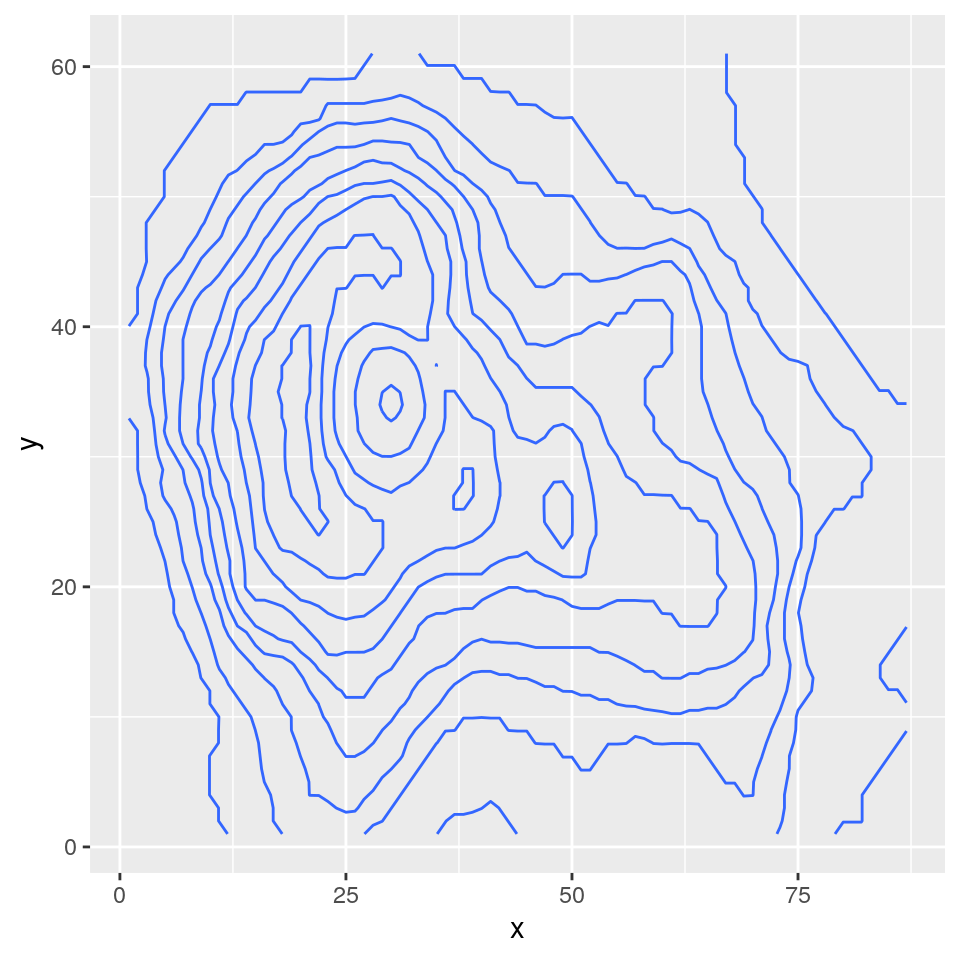
Se vogliamo evidenziare i livelli sull’asse z con colori, possiamo modificare la geometria e i colori riportati:
ggp <- ggplot(volcano3d, aes(x = x, y = y, z = z)) +
stat_contour(geom = "polygon", aes(fill = ..level..))
print(ggp)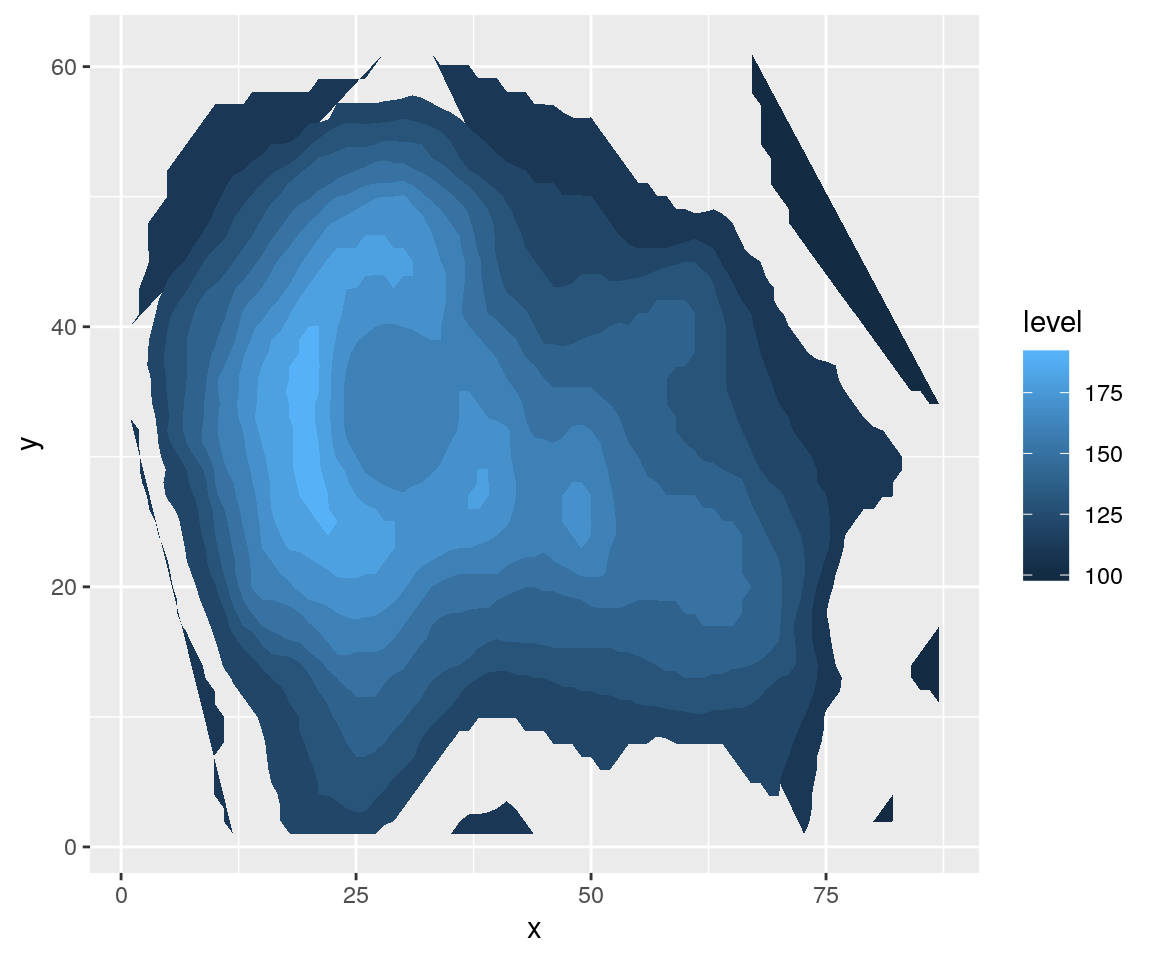
Questa raprpesentazione grafica aiuta ad evidenziare le aree più “basse” (colore blu più scuro) da quelle più “alte” (colore più chiaro).
Purtroppo però la rappresentazione non è molto chiara perché per valori troppo bassi non è stato assegnato un colore.
Per questa ragione si può generare un grafico a “mattonelle” (“tile”) con le curve di livello sovraimpresse
ggp <- ggplot(volcano3d, aes(x = x, y = y, z = z)) +
geom_tile(aes(fill = z)) +
stat_contour()
print(ggp)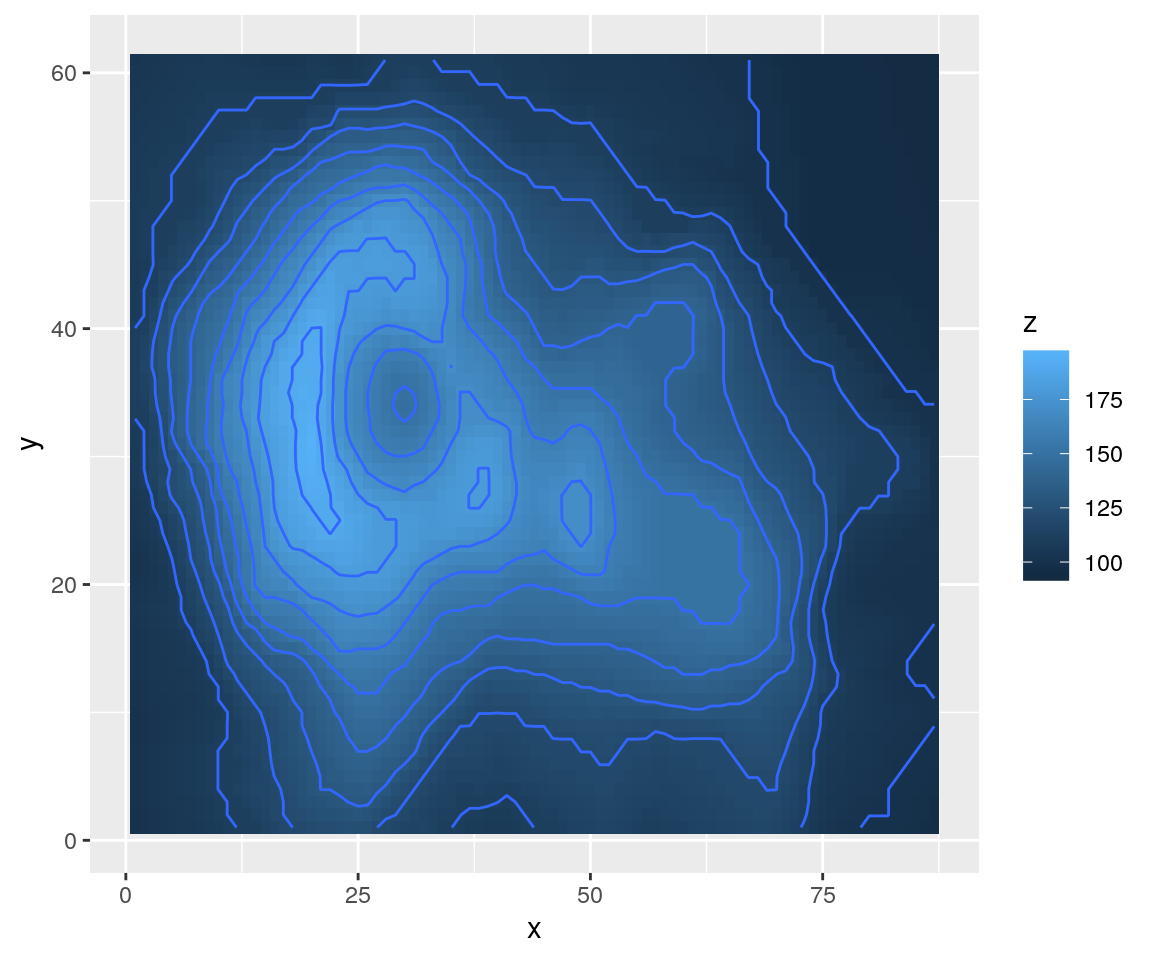
Se invece volessimo generare una sorta di density plot (“istogramma”) bivariato, allora possiamo usare la funzione stat_density2d():
ggp <- ggplot(forbes94, aes(x = Sales, y = Profits)) +
stat_density2d(aes(fill = ..level..), geom = "polygon")
print(ggp)## Warning: Removed 4 rows containing non-finite values (stat_density2d).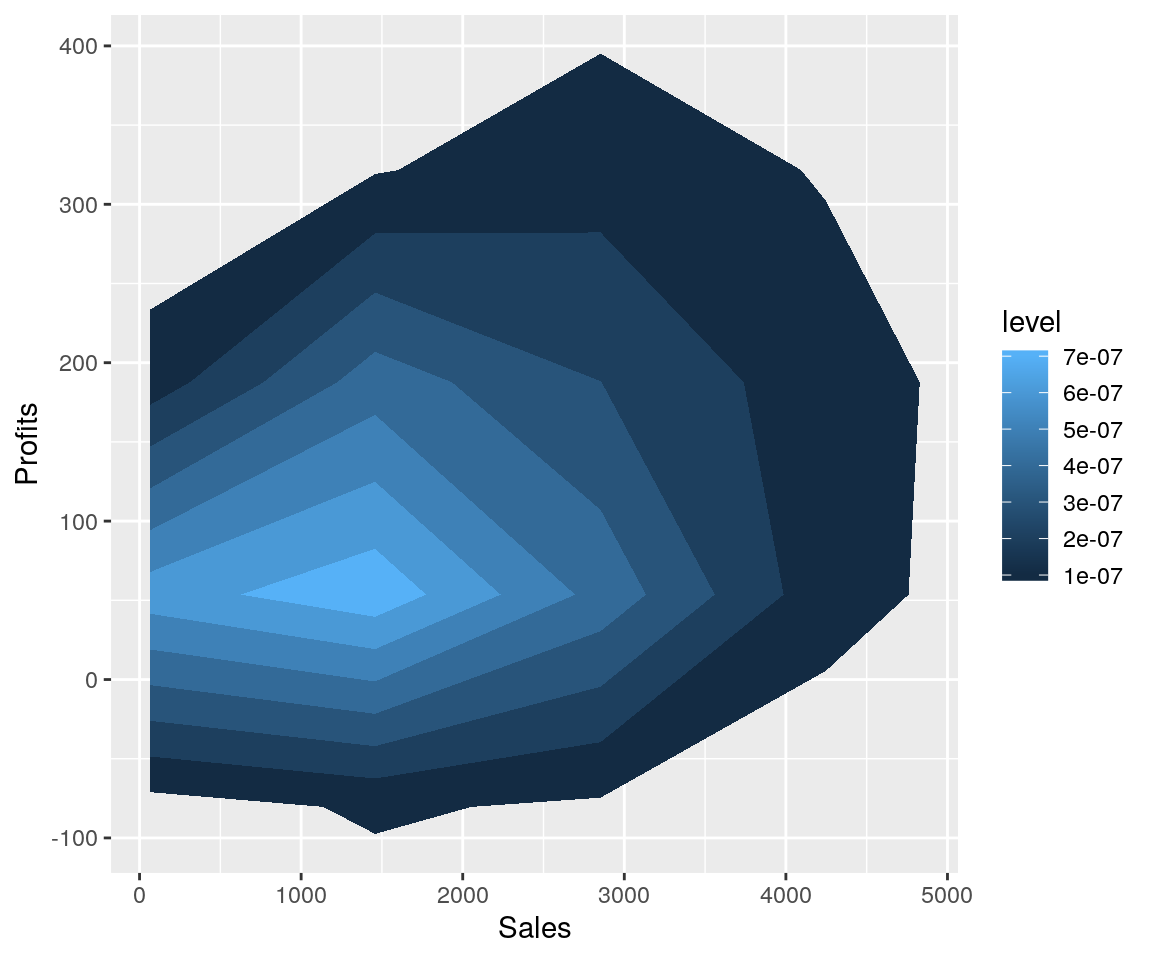
Questo grafico riporta su aree di livello il density plot bivariato ottenuto associando i valori di vendite (Sales) e profitti (Profit) del dataset forbes94.
2.6.2 3D Scatterplots
Se poi si volessero generare delle “vere” rappresentazioni tridimensionali dei dati a disposizione, ci sono comunque delle opzioni disponibili. Di seguito presenteremo alcuni semplici esempi che usano il package rgl.
Provate questi esempi direttamente in R, poiché i grafici prodotti sono interattivi e quindi non possono essere “provati” direttamente cliccandoci sopra col mouse.
Negli esempi che seguono, notate l’uso della funzione with(): questa serve per indicare al codice che tutto quello che appare come secondo argomento della funzione stessa “fa riferimento” ai dati indicati nel primo argomento della funzione.
Per esempio, qui sotto, le variabili StockOwned, Sales e Profits sono colonne del data frame forbes94:
open3d()
with(forbes94,
plot3d(x = StockOwned, y = Sales, z = Profits,
xlab = "StockOwned", ylab = "Sales", zlab = "Profits", type = "p"
))2.6.3 Superfici 3D
Ovviamente si possono anche generare superfici 3D esploraibili interattivamente. Un esempio copia/incollabile lo trovate qui di seguito:
z <- 2 * volcano # Esagera il rilievo
x <- 10 * (1:nrow(z)) # griglia di 10 metri (da S a N)
y <- 10 * (1:ncol(z)) # griglia di 10 metri (da E a O)
zlim <- range(z)
zlen <- zlim[2] - zlim[1] + 1
colorlut <- terrain.colors(zlen) # Tabella di colori per rappresentare le altezze
col <- colorlut[ z - zlim[1] + 1 ] # assegna i colori alle altezze per ogni punto
open3d()
surface3d(x, y, z, color = col, back = "lines")