Capitolo 21 Random Forest (RF)
21.1 Introduzione
La tecnica delle foreste casuali (Random Forest) è spesso considerata una panacea per tutti i problemi di data science. In maniera scherzosa, potremmo dire che quando non sai quale algoritmo usare (indipendentemente dalla situazione), puoi usare le random forest!
Random Forest è un metodo versatile di machine learning, capace di affrontare sia compiti di classificazione che di regressione. Con le foreste casuali è anche possibile applicare metodi per la riduzione della dimensionalità, gestire dati mancanti, valori degli outlier ed altri passaggi essenziali di esplorazione dei dati, producendo buoni risultati. Per avere una presentazione più completa si veda per esempio Hastie, T., Tibshirani, R., and Friedman, J., The Elements of Statistical Learning, 2nd edition, Springer, 2009.
Il bagging, o bootstrap aggregation, è una tecnica per ridurre la varianza di una funzione di previsione stimata. Il bagging sembra funzionare specialmente bene con procedure ad alta varianza e bassa distorsione, quali gli alberi. Per la regressione, si adatta semplicemente molte volte lo stesso albero di regressione su versioni campionate via bootstrap dei dati di training, e si calcola una media dei risultati. Per la classificazione, si adatta un “comitato” di alberi, ognuno dei queli esprime un voto per la classe prevista.
Le foreste casuali (Breiman, 2001) sono una modifica del metodo di bagging che costruisce una grande raccolta di alberi de-correlati, e quindi ne calcola la media. In molti problemi, le performance delle foreste casuali sono elevate; le foreste casuali sono inoltre semplici da addestrare e regolarizzare. Di conseguenza le random forest sono diventate piuttosto popolari.
21.2 Esempio: Boston housing
Probabilmente il package R più importante che implementa le foreste casuali è
randomForest.
L’esempio che segue, basato su dati di Boston housing visti anche in precedenza con gli alberi di regressione, userà quindi la
funzione randomForest() del package randomForest.
Diamo prima un’occhiata al riepilogo dei dati di esempio:
## crim zn indus chas nox
## Min. : 0.00632 Min. : 0.00 Min. : 0.46 0:471 Min. :0.3850
## 1st Qu.: 0.08204 1st Qu.: 0.00 1st Qu.: 5.19 1: 35 1st Qu.:0.4490
## Median : 0.25651 Median : 0.00 Median : 9.69 Median :0.5380
## Mean : 3.61352 Mean : 11.36 Mean :11.14 Mean :0.5547
## 3rd Qu.: 3.67708 3rd Qu.: 12.50 3rd Qu.:18.10 3rd Qu.:0.6240
## Max. :88.97620 Max. :100.00 Max. :27.74 Max. :0.8710
## rm age dis rad
## Min. :3.561 Min. : 2.90 Min. : 1.130 Min. : 1.000
## 1st Qu.:5.886 1st Qu.: 45.02 1st Qu.: 2.100 1st Qu.: 4.000
## Median :6.208 Median : 77.50 Median : 3.207 Median : 5.000
## Mean :6.285 Mean : 68.57 Mean : 3.795 Mean : 9.549
## 3rd Qu.:6.623 3rd Qu.: 94.08 3rd Qu.: 5.188 3rd Qu.:24.000
## Max. :8.780 Max. :100.00 Max. :12.127 Max. :24.000
## tax ptratio b lstat medv
## Min. :187.0 Min. :12.60 Min. : 0.32 Min. : 1.73 Min. : 5.00
## 1st Qu.:279.0 1st Qu.:17.40 1st Qu.:375.38 1st Qu.: 6.95 1st Qu.:17.02
## Median :330.0 Median :19.05 Median :391.44 Median :11.36 Median :21.20
## Mean :408.2 Mean :18.46 Mean :356.67 Mean :12.65 Mean :22.53
## 3rd Qu.:666.0 3rd Qu.:20.20 3rd Qu.:396.23 3rd Qu.:16.95 3rd Qu.:25.00
## Max. :711.0 Max. :22.00 Max. :396.90 Max. :37.97 Max. :50.00Prepariamo quindi i dati per l’analisi
set.seed(100)
bostonhousing$chas <- factor(bostonhousing$chas, levels = 0:1, labels = c("no", "yes"))
bostonhousing$rad <- factor(bostonhousing$rad, ordered = TRUE)
bostonhousing <- bostonhousing %>%
select(medv, age, lstat, rm, zn, indus, chas, nox, age, dis, rad, tax, crim, b, ptratio)
train <- sample(nrow(bostonhousing), 400)
bh_train <- bostonhousing[train,]
bh_test <- bostonhousing[-train,]
(rf_fit <- randomForest(medv ~ ., data = bh_train))##
## Call:
## randomForest(formula = medv ~ ., data = bh_train)
## Type of random forest: regression
## Number of trees: 500
## No. of variables tried at each split: 4
##
## Mean of squared residuals: 10.17175
## % Var explained: 87.27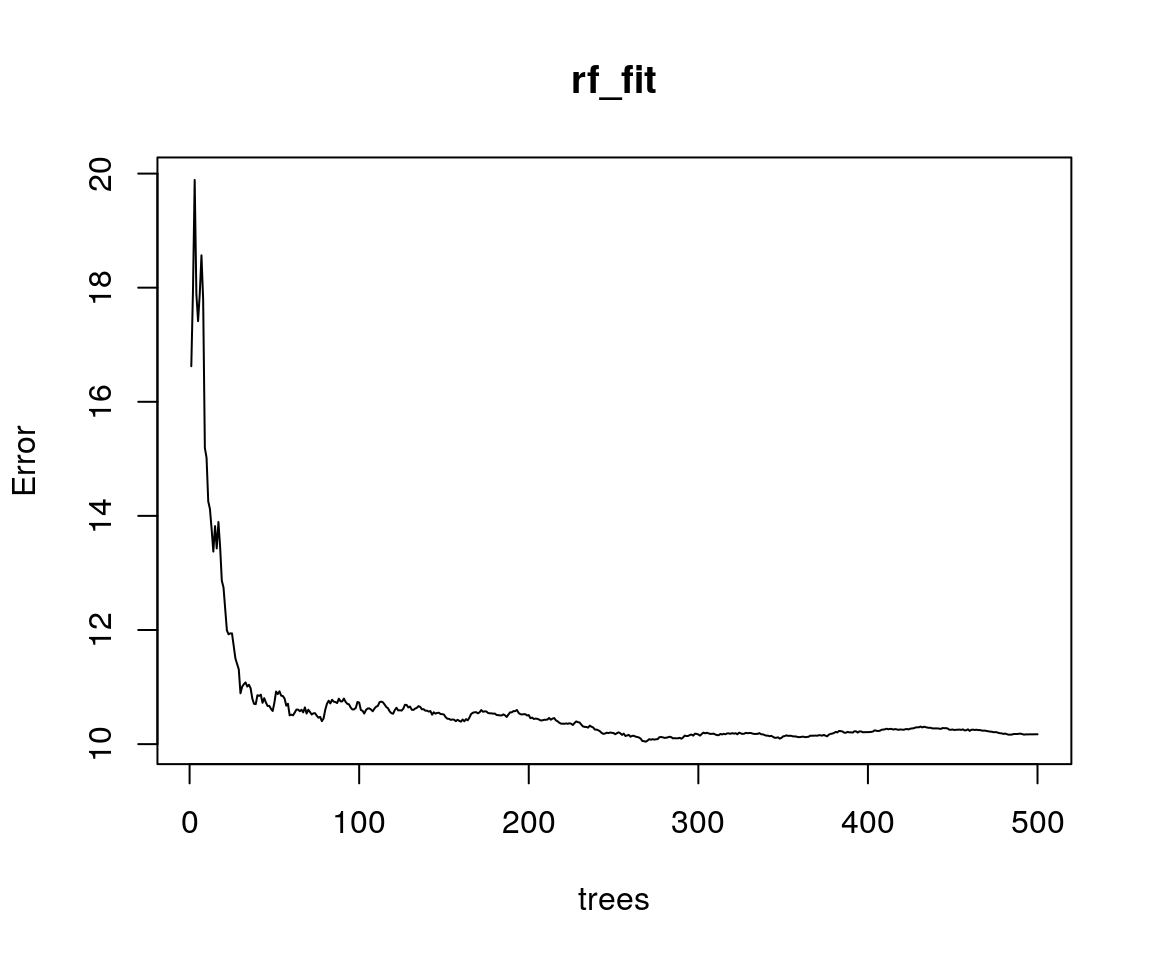
Si noti come in questo caso, a differenza dei modelli party, non sia necessario trasformare le variabili
lstat e rm (usate nelle regressioni del modello party), poiché le foreste casuali, in qualità raccolta
di alberi di regressione, sono in grado di “intercettare”
anche relazioni non lineari tra la variabile dipendente e le variabili indipendenti.
In ogni modo, nel grafico qui sopra, la linea continua nera mostra l’errore complessivo della foresta casuale
quando il numero di alberi \(B\) cresce. In questo csao, un numero di alberi inferiore a 500
è ampiamente sufficiente a minimizzare l’errore global.
Ovviamente, possiamo produrre un grafico dei valori osservati Vs. i valori previsti, sia per l’insieme dei dati di training sia per quello di test:
data_gr <- bh_train %>%
mutate(set="train") %>%
bind_rows(bh_test %>% mutate(set="test"))
data_gr$fit <- predict(rf_fit, data_gr)
library(ggplot2)##
## Attaching package: 'ggplot2'## The following object is masked from 'package:randomForest':
##
## marginggp <- ggplot(data = data_gr, mapping = aes(x=fit, y=medv)) +
geom_point(aes(colour=set), alpha=0.6) +
geom_abline(slope=1, intercept = 0) +
geom_smooth(method = "lm", se = FALSE, aes(colour=set), alpha=0.6)
print(ggp)
Il modello di foresta casuale mostrato sopra estrae casualmente per ogni split 4 variabili da considerare per lo split stesso. Potremmo provare a vedere cosa accade facendo variare il numero di predittori estratti tra 1 e tutti i 13 possibili predittori utilizzabili ad ogni split.
set.seed(100)
oob_err <- double(13)
test_err <- double(13)
#mtry è il numero di variabili scelte caualmente ad ogni split
for(mtry in 1:13)
{
rf <- randomForest(medv ~ . , data = bh_train, mtry=mtry,ntree=400)
oob_err[mtry] <- rf$mse[400] #Errore per tutti gli alberi adattati
pred <- predict(rf,bh_test) #Previsioni sul set di test per ciascun albero
test_err[mtry] <- with(bh_test, mean( (medv - pred)^2)) #Mean Squared Error per l'insieme di test
}
# Errore sull'insieme di Test
test_err## [1] 28.21875 19.55995 17.51116 16.42723 16.63094 15.60248 16.48503 16.14524
## [9] 17.02976 16.84301 17.57899 17.91067 17.81792## [1] 19.310462 12.309479 11.158004 9.985156 9.395468 9.972013 9.516923
## [8] 9.839743 9.792508 9.876895 9.724254 10.430090 10.716280Ora possiamo tracciare graficamente l’Errore dell’insieme di test e l’Errore Out of Bag
ds_gr <- data_frame(type=c(rep("test", length(test_err)), rep("oob", length(oob_err))),
mtry = c(1:length(test_err), 1:length(oob_err)),
error=c(test_err, oob_err))## Warning: `data_frame()` is deprecated, use `tibble()`.
## This warning is displayed once per session.ggp <- ggplot(data = ds_gr, mapping = aes(x=mtry,y=error)) +
geom_line(aes(colour=type)) +
geom_point(aes(colour=type)) +
ggtitle("OOB e Errore di test error Vs. Numero di variabili negli split (mtry)")
print(ggp)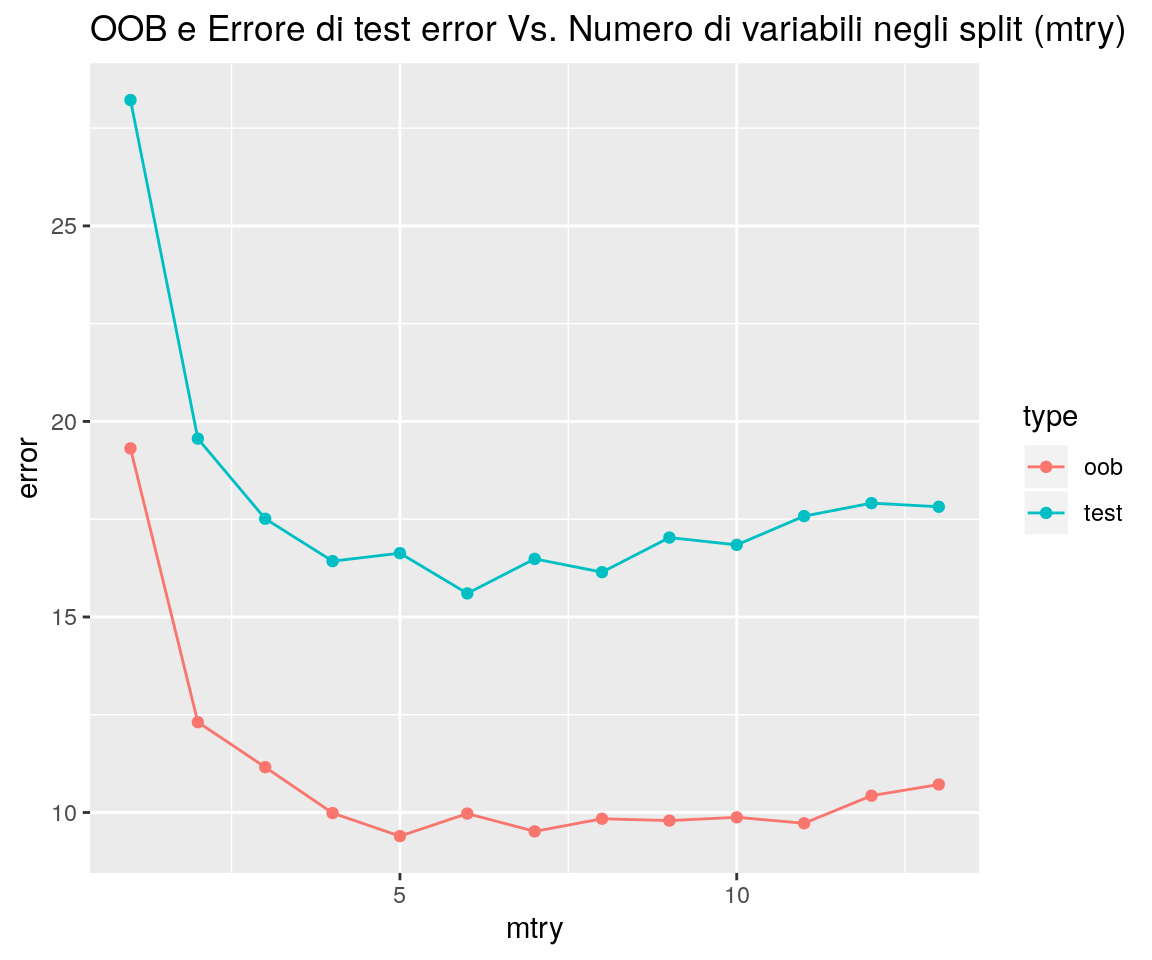
Possiamo osservare che la linea rossa mostra le stime Out of Bag dell’errore, mentre la
linea blu rappresenta il valore dell’errore calcolato sull’insieme di Test. Entrambe le curve
sono abbastanza regolari e le stime dell’errore sono in qualche modo correlate.
Sia l’errore di Test (se viene usato come insieme di validazione, ma di questo magari ne parleremo un’altra volta),
sia l’errore OOB (“lisciandone” l’andamento), tendono a minimizzarsi intorno a mtry = 6.
L’asse delle acisse mostra il numero dei predittori da cui estrarre split; all’estrema
destra si ha mtry = 13, che corrisponde al solo Bagging (non discusso ancora in questo materiale).
Ora possiamo quindi provare il modello con mtry = 6.
##
## Call:
## randomForest(formula = medv ~ ., data = bh_train, mtry = 6)
## Type of random forest: regression
## Number of trees: 500
## No. of variables tried at each split: 6
##
## Mean of squared residuals: 9.879587
## % Var explained: 87.64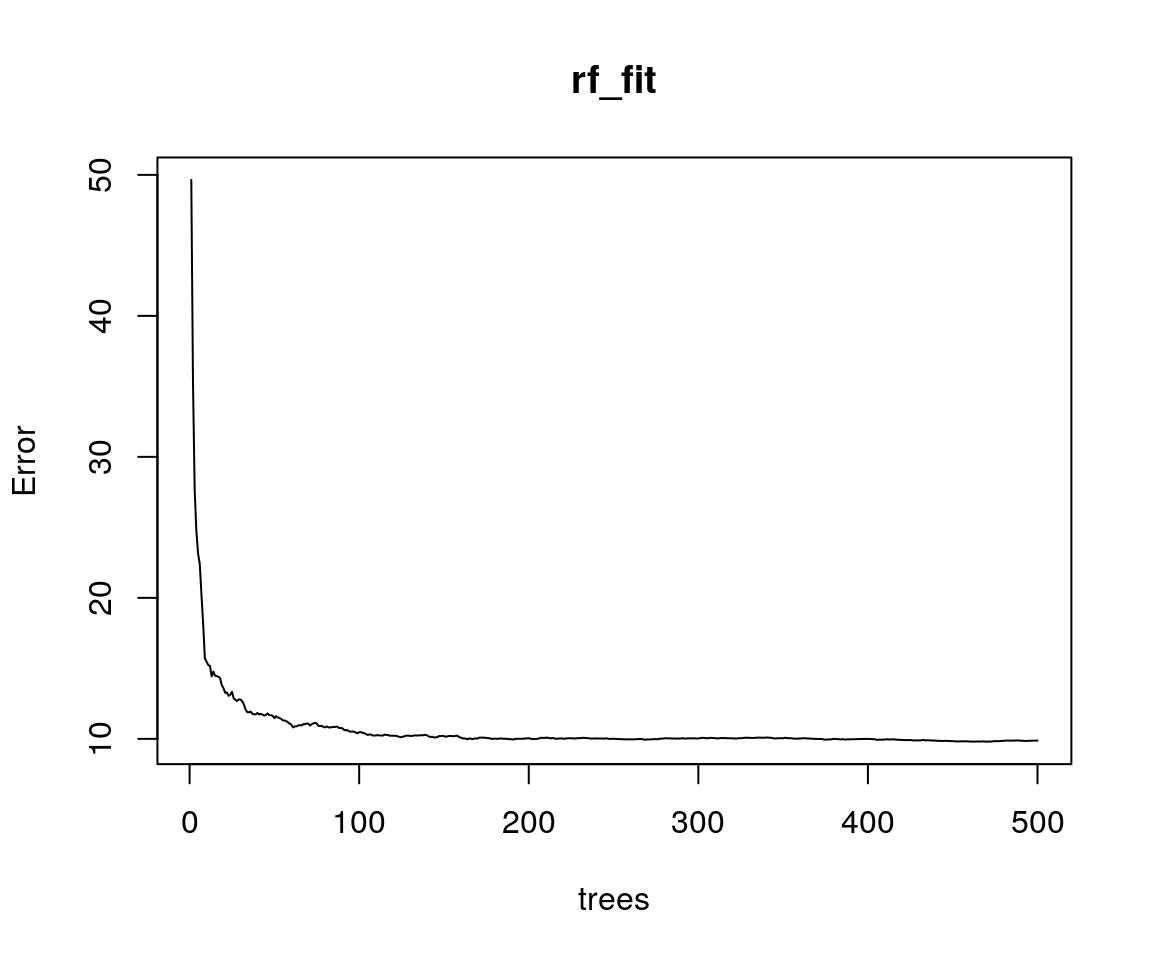
data_gr <- bh_train %>%
mutate(set="train") %>%
bind_rows(bh_test %>% mutate(set="test"))
data_gr$fit <- predict(rf_fit, data_gr)
mse <- data_gr %>%
filter(set=="test") %>%
summarise(mse = mean((fit-medv)^2)) %>%
pull()
print(mse)## [1] 16.24758ggp <- ggplot(data = data_gr, mapping = aes(x=fit, y=medv)) +
geom_point(aes(colour=set), alpha=0.6) +
geom_abline(slope=1, intercept = 0) +
geom_smooth(method = "lm", se = FALSE, aes(colour=set), alpha=0.6)
print(ggp)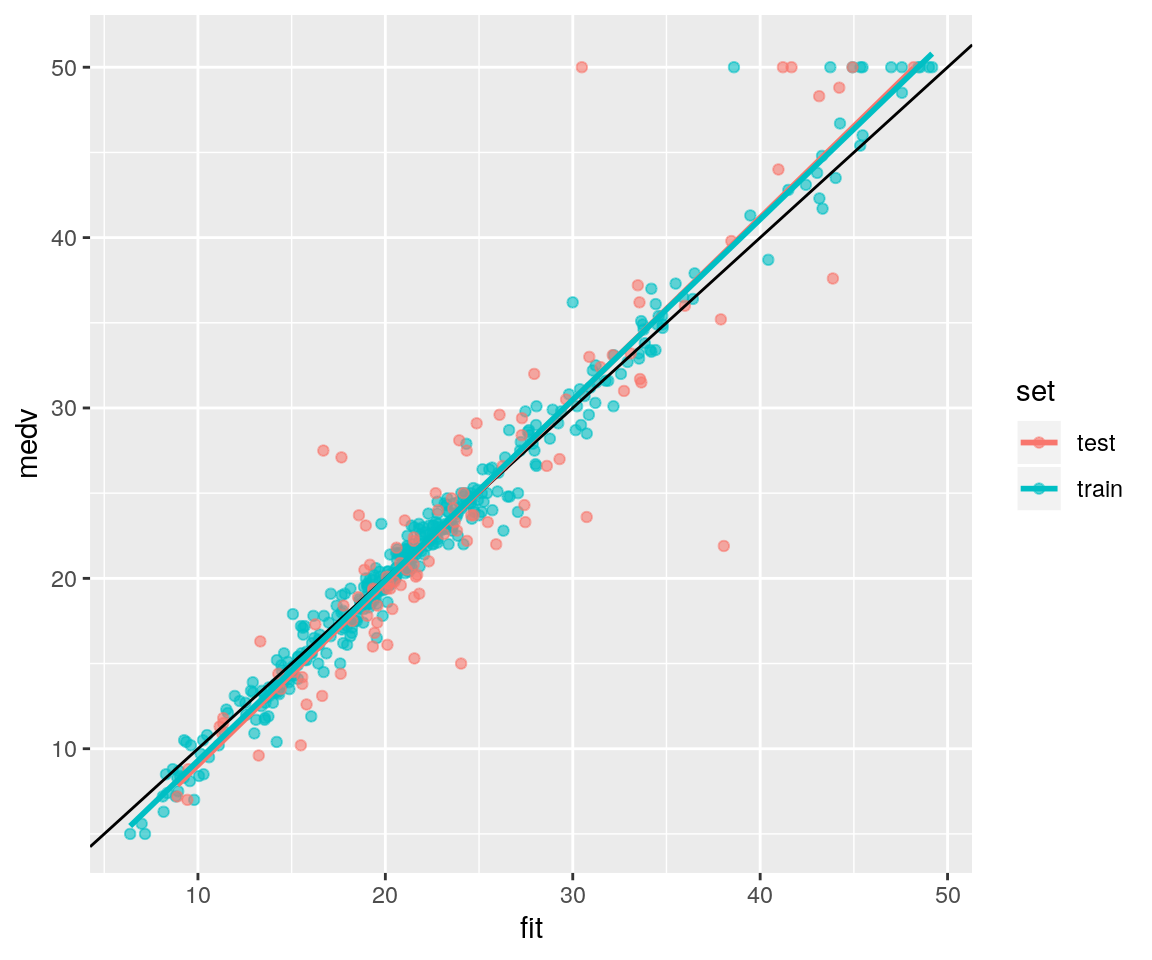
Non sono evidenti grandi differenze rispetto al modello precedente.
L’errore quadratico medio per l’insieme di test è pari a 16.2475782.
21.3 Alcuni cenni di teoria sulle Foreste Casuali
L’idea fondamentale alla base del bagging è quella di calcolare la media di molti modelli contenenti errore ma approssimativamente non distorti, in modo da ridurre la varianza. Gli alberi sono candidati ideali per il bagging, poiché possono catturare strutture di interazione complesse presenti nei dati e, se fatti crescere con sufficiente profondità, hanno una distorsione relativamente bassa. Poiché gli alberi sono notoriamente soggetti ad errore, possono beneficiare in maniera importante dal calcolo della loro media. Perdipiù, poiché ogni albero generato nel bagging proviene da una distribuzione identica (i.d.: identicamente distribuito), il valore atteso di una media di \(B\) tali alberi sarà lo stesso valore atteso di uno qualunque di loro. Ciò significa che la distorsione di alberi “bagged” è la stessa dei singoli alberi, e la sola opzione di miglioramnto sarà tramite la riduzione della varianza. Una media di variabili \(B\) casuali i.i.d., ciascuna con varianza \(\sigma^2\) , ha varianza \(\frac{1}{B} \sigma^2\). Se le variabili sono semplicemente i.d. (identicamente distribuite, ma non necessariamente independenti) con correlazione a coppie \(\rho\) positiva, la varianza della media è \[\rho \sigma^2 + \frac{1-\rho}{B} \sigma^2\] Mano a mano che \(B\) cresce, il secondo termine della somma si riduce, mentre il primo rimane, e quindi la valore della correlazione di coppie di alberi bagged limita i benefici del calcolo della media. L’idea nelle foreste casuali è quella di migliorare la riduzione della varianza del bagging riducendo la correlazione tra gli alberi, senza accrescere troppo la varianza. Questo è raggiunto nel processo di crescita degli alberi attraverso la selezione casuale delle variabili di input.
Nello specifico, quando si fa crescere un albero su un dataset “bootstrapped”:
- Prima di ogni split, seleziona a caso \(m \le p\) delle variabili di input come candidate per lo split
Valori tipici di \(m\) possono andare da \(p\) a valori molto piccoli, quale 1, con valore usualmente preferibile pari a \(p/3\). Dopo aver fatto crescere \(B\) alberi \(\left\{T_b(x; \Theta_b )\right\}_1^B\) in questo modo, il predittore basato su foresta casuale sarà \[\hat{f}_{rf}^B(x) = \frac{1}{B} \sum_{b=1}^B T_b(x; \Theta_b)\] Dove \(\Theta_b\) caratterizza il \(b\)-mo albero della foresta casuale in termini di variabili di split, punto di split in ogni nodo, valori del nodo terminale; \(T_b(x; \Theta_b)\) è la previsione del \(b\)mo albero della foresta casuale. Intuitivamente, la riduzione di \(m\) produrrà una riduzione della correlazione tra coppie di alberi nell’insieme, e quindi ridurrà la varianza della media.
L’algoritmo del Random Forest può quindi essere riassunto come:
- Per \(b = 1 \dots B\):
- Estrai un campione bootstrap \(Z^*\) di dimensione \(N\) dai dati di training.
- Fai crescere un albero \(T_b\) della foresta casuale su dati “bootstrapped”, ripetendo ricorsivamente i seguenti passaggi per ciascun nodo terminale dell’albero, fino al raggiungimento dell dimensione minima dei nodi \(n_{min}\).
- Seleziona \(m\) variabili a caso tra le \(p\) variabili.
- Seleziona la migliore variabile e punto di split tra le \(m\).
- Dividi (split) il nodo in due nodi figli.
- Ritorna l’insieme degli alberi \(\left\{T_b\right\}_1^B\)