Capitolo 16 Random Forest (RF)
16.1 Introduzione
La tecnica delle Random Forest (foreste casuali) è spesso considerata una panacea per tutti i problemi di data science. In maniera scherzosa, potremmo dire che quando non sai quale algoritmo usare (indipendentemente dalla situazione), puoi usare le random forest!
Random Forest è un metodo versatile di machine learning, capace di affrontare sia compiti di classificazione che di regressione. Con le foreste casuali è anche possibile applicare metodi per la riduzione della dimensionalità, gestire dati mancanti, valori degli outlier ed altri passaggi essenziali di esplorazione dei dati, producendo buoni risultati. Per avere una presentazione più completa si veda per esempio Hastie, T., Tibshirani, R., and Friedman, J., The Elements of Statistical Learning, 2nd edition, Springer, 2009.
Il bagging, o bootstrap aggregation, è una tecnica per ridurre la varianza di una funzione di previsione stimata. Il bagging sembra funzionare specialmente bene con procedure ad alta varianza e bassa distorsione, quali gli alberi. Per la regressione, si adatta semplicemente molte volte lo stesso albero di regressione su versioni campionate via bootstrap dei dati di training, e si calcola una media dei risultati. Per la classificazione, si adatta un “comitato” di alberi, ognuno dei quali esprime un voto per la classe prevista.
Le foreste casuali (Breiman, 2001) sono una modifica del metodo di bagging che costruisce una grande raccolta di alberi de-correlati, e quindi ne calcola la media. In molti problemi, le performance delle foreste casuali sono elevate; le foreste casuali sono inoltre semplici da addestrare e regolarizzare. Per queste ragioni le random forest sono diventate piuttosto popolari.
16.2 Esempio: Default carte di credito
Probabilmente il package R più importante che implementa le foreste casuali è
randomForest.
L’esempio che segue, basato su dati di default delle carte di credito visti anche in precedenza, userà quindi la
funzione randomForest() del package randomForest.
Diamo prima un’occhiata al riepilogo dei dati di esempio:
## default student balance income
## No :9667 No :7056 Min. : 0.0 Min. : 772
## Yes: 333 Yes:2944 1st Qu.: 481.7 1st Qu.:21340
## Median : 823.6 Median :34553
## Mean : 835.4 Mean :33517
## 3rd Qu.:1166.3 3rd Qu.:43808
## Max. :2654.3 Max. :73554Carichiamo quindi il package per l’analisi
E lanciamo l’analisi stessa
set.seed(1000)
train <- sample(nrow(Default), 2000)
default_train <- Default[train,]
default_test <- Default[-train,]
(rf_fit <- randomForest(x= default_train[,c("student","balance", "income")], y = default_train$default,
xtest= default_test[,c("student","balance", "income")], ytest = default_test$default,
cutoff = c(0.8, 0.2)))##
## Call:
## randomForest(x = default_train[, c("student", "balance", "income")], y = default_train$default, xtest = default_test[, c("student", "balance", "income")], ytest = default_test$default, cutoff = c(0.8, 0.2))
## Type of random forest: classification
## Number of trees: 500
## No. of variables tried at each split: 1
##
## OOB estimate of error rate: 3%
## Confusion matrix:
## No Yes class.error
## No 1911 21 0.01086957
## Yes 39 29 0.57352941
## Test set error rate: 3%
## Confusion matrix:
## No Yes class.error
## No 7655 80 0.0103426
## Yes 160 105 0.6037736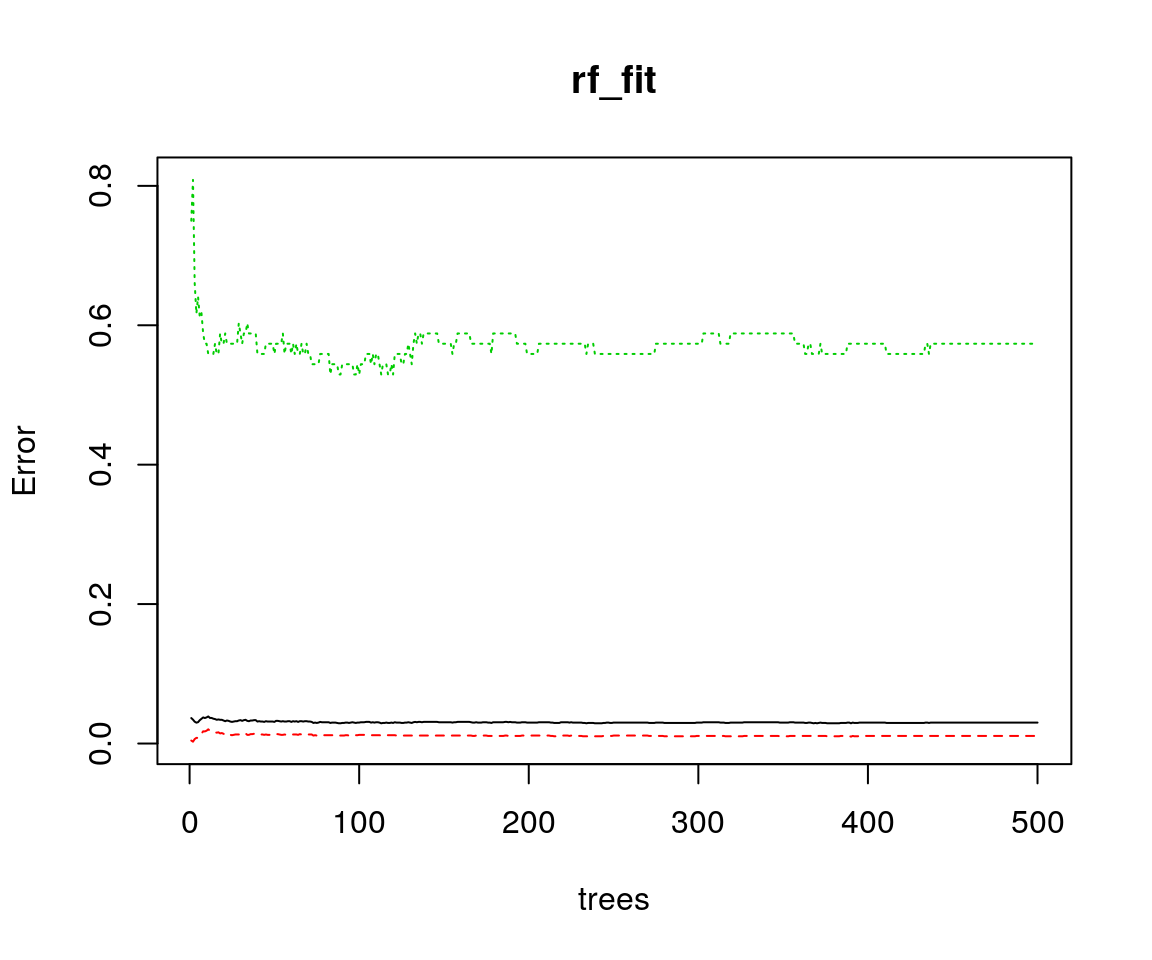
Nel grafico qui sopra, la linea continua nera mostra l’errore OOB (Out Of Bag) complessivo della foresta casuale, mano a mano che il numero di alberi \(B\) cresce; le altre linee, invece, mostrano l’errore di classificazione OOB per le singole classi. In questo caso, sono sufficienti meno di 50 alberi per minimizzare l’errore globale.
Si noti anche l’uso del parametro cutoff che imposta la soglia per cui dichiarare
“defaulter” un cliente.
In questo caso abbiamo scelto l’insieme di valori di cutoff uguali a c(0.8, 0.2), cioè,
un cliente è definito defaulter se ottiene un valore di alberi che votano defaulter maggiore di 0.2.
Questo corrisponde a uno schema di voting pwsato in cui un voto per la classe default ha un peso pari
a quattro volte la classe non-default.
Questo risultato ha una maggiore sensibilità quindi verso i defaulter rispetto al cutoff (50%, 50%).
16.3 Alcuni cenni di teoria sulle Foreste Casuali
L’idea fondamentale alla base del bagging è quella di calcolare la media di molti modelli contenenti errore ma approssimativamente non distorti, in modo da ridurre la varianza. Gli alberi sono candidati ideali per il bagging, poiché possono catturare strutture di interazione complesse presenti nei dati e, se fatti crescere con sufficiente profondità, hanno una distorsione relativamente bassa. Poiché gli alberi sono notoriamente soggetti ad errore, possono beneficiare in maniera importante dal calcolo della loro media. Perdipiù, poiché ogni treno generato nel bagging proviene da una distribuzione identica (i.d.: identicamente distribuito), il valore atteso di una media di \(B\) tali alberi sarà lo stesso valore atteso di uno qualunque di loro. Ciò significa che la distorsione di alberi “bagged” è la stessa dei singoli alberi, e la sola opzione di miglioramnto sarà tramite la riduzione della varianza. Una media di variabili \(B\) casuali i.i.d., ciascuna con varianza \(\sigma^2\) , ha varianza \(\frac{1}{B} \sigma^2\). Se le variabili sono semplicemente i.d. (identicamente distribuite, ma non necessariamente independenti) con correlazione a coppie \(\rho\) positiva, la varianza della media è \[\rho \sigma^2 + \frac{1-\rho}{B} \sigma^2\] Mano a mano che \(B\) cresce, il secondo termine della somma si riduce, mentre il primo rimane, e quindi la dimensione della correlazione correlation di coppie di alberi bagged limita i benefici del calcolo della media. L’idea nelle foreste casuali è quella di migliorare la riduzione della varianza del bagging riducendo la correlazione tra gli alberi, senza accrescere troppo la varianza. Questo è raggiunto nel processo di crescita degli alberi attraverso la selezione casuale delle variabili di input.
Nello specifico, quando si fa crescere un albero su un dataset “bootstrapped”:
- Prima di ogni split, seleziona a caso \(m \le p\) delle variabili di input come candidate per lo split
Valori tipici di \(m\) possono andare da \(p\) a valori molto piccoli, quale 1, con valore usualmente preferibile pari a \(\sqrt{p}\). Dopo aver fatto crescere \(B\) alberi \(\left\{T_b(x; \Theta_b )\right\}_1^B\) in questo modo, il predittore basato su foresta casuale di classificazione sarà \[\hat{C}_{rf}^B(x) = majority vote \left\{ \hat{C}_b(x)\right\}_1^B\] Dove \(majority vote\) indica la classe più “votata”, e \(\Theta_b\) caratterizza il \(b\)mo albero della foresta casuale in termini di variabili di split, punto di split in ogni nodo, valori del nodo terminale; \(\hat{C}_b(x)\) è la classe prevista dal \(b\)mo albero della foresta casuale. Intuitivamente, la riduzione di \(m\) produrrà una riduzione della correlazione tra coppie di alberi nell’insieme, e quindi ridurrà la varianza della media.
L’algoritmo del Random Forest può quindi essere riassunto come:
- Per \(b = 1 \dots B\):
- Estrai un campione bootstrap \(Z^*\) di dimensione \(N\) dai dati di training.
- Fai crescere un albero \(T_b\) della foresta casuale su dati “bootstrapped”, ripetendo ricorsivamente i seguenti passaggi per ciascun nodo terminale dell’albero, fino al raggiungimento dell dimensione minima dei nodi \(n_{min}\).
- Seleziona \(m\) variabili a caso tra le \(p\) variabili.
- Seleziona la migliore variabile e punto di split tra le \(m\).
- Dividi (split) il nodo in due nodi figli.
- Ritorna l’insieme degli alberi \(\left\{T_b\right\}_1^B\)