Capitolo 5 Introduzione all’Analisi delle Corrispondenze (CA)
5.1 Introduzione
L’Analisi delle Corrispondenze (CA) è una forma di scaling multidimensionale, che essenzialmente costruisce una sorta di modello spaziale che mostra le associazioni tra un insieme di variabili categoriali. Se l’insieme include solo due variabili, il metodo è usualmente chiamato Analisi delle Corrispondenze Semplici (SCA). SCA è spesso usato per integrare un test chi-quadro standard di indipendenza per due variabili categoriali che formano una tabella di contingenza. Se l’analisi coinvolge più di due variabili, allora è usualmente chiamata Analisi delle Corrispondenze Multiple (MCA). Qui di seguito presenteremo brevemente un esempio di SCA. Una illustrazione più approfondita sia sulla SCA che sulla MCA si può trovare in qualunque testo sull’analisi di dati multivariata (si veda per esempio Johnson, R. and Wichern, D., Applied Multivariate Statistical Analysis, 6th edition, Pearson, 2014).
Consideriamo quindi una generica tabella di contigenza bidimensionale in cui ci sono \(R\) righe e \(C\) colonne. A partire da questa tabella possiamo costruire le tabelle delle proporzioni di riga e delle proporzioni di colonna. La quantità fondamentale calcolata in una CA è la distanza secondo la metrica del chi-quadro tra colonne e la distanza secondo la metrica del chi-quadro tra righe delle tabella. La distanza del chi-quadro può essere considerata una distanza euclidea ponderata basata sulle proporzioni di colonna (o riga). La distanza tra due colonne (o righe) sarà nulla se le due colonne (righe) contengono gli stessi valori di proporzione.
Una CA è ottenuta sostanzialmente applicando l’MDS alle matrici di distanza (di riga o di colonna) e tracciando (usualmente) le prime due coordinate per le categorie di colonna e le categorie di riga sullo stesso diagramma. L’interpretazione del grafico risultante può essere riassunto come segue:
- La prossimità di due punti indicanti righe (colonne) indica un profilo simile nelle corrispondenti righe (colonne), dove “profilo” indica la distribuzione di frequenza condizionata delle riga (colonna); queste due righe (colonne) sono quindi quasi proporzionali. Interpretazione opposta si applica quando le due righe (colonne) sono invece distanti.
- La prossimità di un punto di riga con un punto di colonna indica che la riga (colonna) ha un peso particolarmente importante sulla colonna (riga). In contrapposizione a questo, un punto di riga che si trova piuttosto distante da un particolare punto di colonna indica che non ci sono quasi osservazioni nella colonna per quella riga (e viceversa). In altre parole, i punti di riga che si trovano vicini a punti di colonna rappresentano una combinazione riga/colonna che si presenta più di frequente di quanto atteso qualora le variabili di riga e di colonna fossero indipendenti. Al contrario, punti di riga e colonna che si trovano distanti tra loro indicamo una cella nella tabella in cui la frequenza è inferiore rispetto a quanto ci si sarebbe atteso sotto l’ipotesi di indipendenza. Queste conclusioni poi sono particolarmente valide quando i punti si trovano distanti dall’origine degli assi.
- L’origine degli assi è la media dei fattori di riga e di colonna. Di conseguenza, un punto (di riga o di colonna) proiettato che si trovi vicino all’origine indica un profilo medio.
- Tutte le interpretazioni indicate qui sopra devono essere ovviamente sostenute sulla base della qualità della rappresentazione grafica, che è valutata, come nella PCA, usando la percentuale di variabilità cumulata spiegata.
In R ci sono molte funzioni per condurre una CA, quali corresp() e
mca() del package MASS, per eseguire SCA e MCA, rispettivamente. Qui ci
concentreremo sul package ca, che fornisce molte funzioni per eseguire diversi
tipi di CA.
5.2 Esempio: Tasso di criminalità negli U.S.A.
Considereremo il dataset uscrime, che fornisce il numero di crimini (ogni 100,000 residenti) negli stati degli Stati Uniti, classificati nel 1985 secondo le seguenti categorie: murder (omicidio), rape (stupro), robbery (rapina), assault (aggressione), burglary (effrazione, furto con scasso), larceny (furto) e auto-theft (furto d’auto). Poiché i dati sono espressi in tassi, prima li trasformeremo in numero di crimini (si noti che la popolazione riportata è in migliaia di persone):
library(pdataita)
data("uscrime")
# Prepara i dati passando da percentuali a valori assoluti
states <- uscrime$state
uscrime <- data.frame(uscrime[,-1])
rownames(uscrime) <- states
uscrime.old <- uscrime
uscrime[, 3:9] <- round(uscrime.old[, 3:9]*uscrime.old[, 2]/100)
summary(uscrime)## land popu1985 murd rape
## Min. : 1212 Min. : 509 Min. : 3.00 Min. : 35.0
## 1st Qu.: 37241 1st Qu.: 1236 1st Qu.: 55.25 1st Qu.: 139.2
## Median : 56214 Median : 3266 Median : 197.50 Median : 497.0
## Mean : 72374 Mean : 4762 Mean : 378.56 Mean : 896.3
## 3rd Qu.: 83242 3rd Qu.: 5654 3rd Qu.: 486.50 3rd Qu.: 981.8
## Max. :591004 Max. :26365 Max. :1899.00 Max. :9254.0
## robb assa burg larc
## Min. : 41.0 Min. : 144 Min. : 1959 Min. : 5184
## 1st Qu.: 689.8 1st Qu.: 1260 1st Qu.: 9345 1st Qu.: 23000
## Median : 2128.5 Median : 3925 Median : 32154 Median : 55204
## Mean : 7657.5 Mean : 7893 Mean : 52014 Mean :100690
## 3rd Qu.: 5881.5 3rd Qu.: 8583 3rd Qu.: 52316 3rd Qu.:110307
## Max. :78832.0 Max. :59585 Max. :462178 Max. :902210
## auto reg div
## Min. : 623 Min. :1.00 Min. :1.00
## 1st Qu.: 3780 1st Qu.:2.00 1st Qu.:3.00
## Median : 9826 Median :3.00 Median :5.00
## Mean : 21246 Mean :2.66 Mean :5.12
## 3rd Qu.: 22443 3rd Qu.:3.75 3rd Qu.:7.75
## Max. :181655 Max. :4.00 Max. :9.00Ora eseguiamo la CA usando la funzione ca() e rappresentiamo graficamente il
risultato:
##
## Principal inertias (eigenvalues):
##
## dim value % cum% scree plot
## 1 0.019891 51.3 51.3 *************
## 2 0.009090 23.5 74.8 ******
## 3 0.006032 15.6 90.4 ****
## 4 0.003328 8.6 99.0 **
## 5 0.000234 0.6 99.6
## 6 0.000172 0.4 100.0
## -------- -----
## Total: 0.038747 100.0
##
##
## Rows:
## name mass qlt inr k=1 cor ctr k=2 cor ctr
## 1 | ME | 2 759 3 | -188 757 4 | -10 2 0 |
## 2 | NH | 2 416 2 | -129 328 2 | -67 88 1 |
## 3 | VT | 1 277 3 | -162 254 1 | 49 23 0 |
## 4 | MA | 23 606 106 | 239 319 66 | -227 287 129 |
## 5 | RI | 4 592 11 | 75 58 1 | -228 534 25 |
## 6 | CT | 12 326 9 | 0 0 0 | -101 326 13 |
## 7 | NY | 89 925 231 | 301 907 409 | 42 18 17 |
## 8 | NJ | 28 861 24 | 135 551 26 | -101 309 32 |
## 9 | PA | 27 827 20 | 150 769 30 | -41 58 5 |
## 10 | OH | 40 743 13 | 25 48 1 | -95 695 40 |
## 11 | IN | 19 918 5 | -11 13 0 | -93 906 18 |
## 12 | IL | 46 289 51 | 110 279 28 | -21 10 2 |
## 13 | MI | 52 145 29 | 34 53 3 | 44 91 11 |
## 14 | WI | 14 879 40 | -275 665 51 | -156 214 36 |
## 15 | MN | 14 927 11 | -103 339 7 | -135 588 28 |
## 16 | IA | 8 874 24 | -298 736 34 | -129 138 14 |
## 17 | MO | 22 810 4 | 77 803 7 | -7 6 0 |
## 18 | ND | 1 846 7 | -404 718 10 | -171 128 4 |
## 19 | SD | 2 926 5 | -329 917 8 | -33 9 0 |
## 20 | NE | 4 494 5 | -129 379 4 | -71 115 2 |
## 21 | KS | 9 901 13 | -212 865 21 | -44 36 2 |
## 22 | DE | 3 247 1 | -34 92 0 | -45 156 1 |
## 23 | MD | 21 407 22 | 118 353 15 | 46 54 5 |
## 24 | VA | 20 824 10 | -129 824 17 | -2 0 0 |
## 25 | WV | 3 956 3 | -156 565 3 | 130 391 5 |
## 26 | NC | 17 821 68 | -107 76 10 | 336 745 216 |
## 27 | SC | 11 603 14 | -70 100 3 | 157 503 29 |
## 28 | GA | 21 739 8 | -87 498 8 | 60 240 9 |
## 29 | FL | 63 910 29 | -76 334 19 | 100 576 70 |
## 30 | KY | 10 95 5 | 41 94 1 | 5 1 0 |
## 31 | TN | 12 537 18 | 85 125 4 | 155 413 32 |
## 32 | AL | 10 675 23 | -31 11 0 | 242 664 65 |
## 33 | MS | 4 779 16 | -156 142 4 | 329 636 43 |
## 34 | AR | 6 700 15 | -134 186 5 | 223 514 33 |
## 35 | LA | 16 632 11 | 47 81 2 | 123 551 26 |
## 36 | OK | 10 852 4 | -118 846 7 | 10 6 0 |
## 37 | TX | 70 910 9 | -49 480 9 | 47 430 17 |
## 38 | MT | 2 910 7 | -285 793 10 | -109 117 3 |
## 39 | ID | 3 907 12 | -354 883 21 | -58 24 1 |
## 40 | WY | 2 919 5 | -326 872 9 | -75 46 1 |
## 41 | CO | 18 847 5 | -83 594 6 | -54 253 6 |
## 42 | NM | 6 892 4 | -139 882 6 | 15 10 0 |
## 43 | AZ | 20 979 14 | -164 955 27 | -26 24 1 |
## 44 | UT | 7 908 18 | -269 731 26 | -132 177 14 |
## 45 | NV | 6 432 1 | -19 67 0 | -43 365 1 |
## 46 | WA | 23 732 24 | -169 686 32 | -44 46 5 |
## 47 | OR | 13 875 13 | -181 855 22 | -28 20 1 |
## 48 | CA | 175 712 14 | -38 466 13 | -28 246 15 |
## 49 | AK | 2 305 2 | -61 87 0 | -97 218 2 |
## 50 | HI | 6 880 8 | -145 376 6 | -168 504 18 |
##
## Columns:
## name mass qlt inr k=1 cor ctr k=2 cor ctr
## 1 | murd | 2 536 16 | 0 0 0 | 408 536 36 |
## 2 | rape | 5 149 8 | -26 11 0 | 93 138 4 |
## 3 | robb | 40 751 306 | 464 729 435 | 81 22 29 |
## 4 | assa | 41 811 162 | 34 8 2 | 349 804 555 |
## 5 | burg | 273 221 87 | 27 61 10 | 45 161 60 |
## 6 | larc | 528 864 169 | -100 803 264 | -27 61 44 |
## 7 | auto | 111 840 252 | 227 587 288 | -149 253 272 |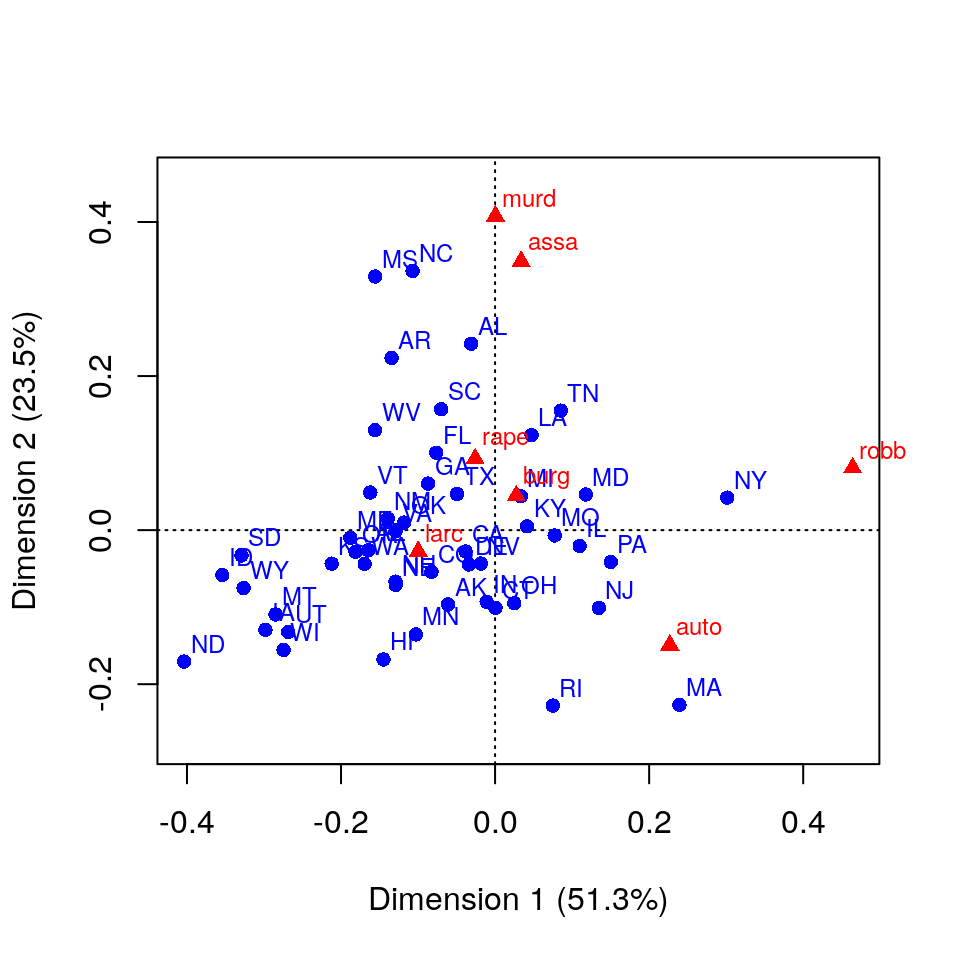
Nella tabella qui sopra, il termine mass indica, rispettivamente, il totale marginale di riga o colonna
per la tabella delle proporzioni totali (moltiplicata per 1000).
qlt significa “qualità”, cioè la somman dei valori di cor (correlazione a quadrato) dei singoli
punti con le componenti selezionate. Il valore di qualità dovrebbe essere confrontato
con la somma delle correlazioni al quadrato per tutte le componenti. Le correlazioni al quadrato
rappresentano l’associazione tra il punto e la data componente. inr
(inerzia) è la proporzione di inerzia (“Chi-quadro di Pearson”) allocata sulla riga
(colonna). ctr sono i contributi delle singole righe (colonne) sulle singole componenti.
Sembra che il primo asse contrapponga robbery (rapina) e larceny (furto) e che il secondo fattore contrapponga assault (aggressione) e murder (omicidio) con auto-theft (furto d’auto). Gi stati che dominano nel primo asse sono gli stati del nord est (MA [Massachussetts] e NY [New York]) Vs. gli stati dell’ovest (WY [Wyoming] e ID [Idaho]). Per il secondo asse, la contrapposizione è tra gli stati del nord (MA [Massachussetts] e RI [Rhode Island]) e gli stati del sud (AL [Alabama], MS [Missisipi] e AR [Arkansas]). Il grafico mostra anche in quali stati la proporzione di una particolare catgoria di crimine è superiore o inferiore rispetto alla media nazionale (l’origine). Notate inoltre che globalmente le prime due dimensioni mostrate permettono di spiegare all’incirca il 74.8% della variabilità totale (chiamata inerzia nella CA).
Possiamo ottenere lo stesso output uando la funzione corresp() del package MASS:
5.3 Alcuni cenni di teoria
Supponiamo di avere un campione di \(n\) osservazioni con 2 variabili categoriali, e supponiamo di produrre una tabella di contingenza (tabella incrociata) a due entrate \((I \times J)\) a partire da queste osservazioni. Chiamiamo \(X\) questa tabella di contingenza. Definiamo ora:
- \(n_{ij}\) l’elemento dell’\(i\)-ma riga e \(j\)-ma colonna della tabella \(X\);
- \(n_{i+}\) il totale della \(i\)-ma riga della tabella;
- \(n_{+j}\) il totale della \(j\)-ma colonna della tabella;
- \(n_{++}\), o semplicemente \(n\), il totale globale della tabella \(X\) (valori \(n_{ij}\));
- \(p_{ij} = n_{ij}/n\);
- \(r_{i}\) o \(p_{i+}\) la massa dell’\(i\)-ma riga, cioè, \(n_{i+}/n\);
- \(c_{j}\) o \(p_{+j}\) la massa della \(j\)-ma colonna, cioè, \(n_{+j}/n\);
- \(a_{ij}\) il \(j\)-mo elemento del profilo della riga \(i\), cioè, \(a_{i,j}=n_{ij}/n_{i+}\); l’\(i\)-mo vettore di profilo di riga è indicato con \(\underline{a}_i\);
- \(b_{ij}\) il \(i\)-mo elemento del profilo della colonna \(j\), cioè, \(b_{i,j}=n_{ij}/n_{+j}\); il \(j\)-mo vettore di profilo di riga è indicato con \(\underline{b}_j\);
- \(\sqrt{\sum_j{(a_{ij}-a_{i'j})^2}/c_j}\) la distanza secondo la metrica del \(\chi^2\) tra l’\(i\)-mo e l’\(i'\)-mo profilo di riga, indicata anche come \(\left \| \underline{a}_i-\underline{a}_{i'} \right \|_c\);
- \(\sqrt{\sum_j{(b_{ij}-b_{ij'})^2}/r_i}\) la distanza secondo la metrica del \(\chi^2\) tra il \(j\)-mo e il \(j'\)-mo profilo di colonna, indicato anche come \(\left \| \underline{b}_j-\underline{b}_{j'} \right \|_r\)
- \(\sqrt{\sum_j{(a_{ij}-c_j)^2}/c_j}\) la distanza secondo la metrica del \(\chi^2\) tra l’\(i\)-mo profilo di riga e il profilo di riga medio \(\underline{c}\) (il vettore delle masse di colonna), indicato anche come \(\left \| \underline{a}_i-\underline{c} \right \|_c\);
- \(\sqrt{\sum_j{(b_{ij}-r_i)^2}/r_i}\) la distanza secondo la metrica del \(\chi^2\) tra il \(j\)-mo profilo di colonna e il profilo di colonna medio \(\underline{r}\) (il vettore delle massi di riga), indicato anche come \(\left \| \underline{b}_j-\underline{r} \right \|_r\)
Definiamo l’Inerzia Totale, come una funzione della tatistica Chi-quadro di Pearson (\(\chi^2\)), come:
\[ \phi = \dfrac{\chi^2}{n}=\sum_i{r_i \left \| \underline{a}_i-\underline{c} \right \|_c} \\ \phantom{\phi = \dfrac{\chi^2}{n}}=\sum_i{r_i \sum_j{ \left(\dfrac{p_{ij}}{r_i} -c_j\right)^2}} \\ \phantom{\phi = \dfrac{\chi^2}{n}}= \sum_j{c_j \left \| \underline{b}_j-\underline{r} \right \|_r} \\ \phantom{\phi = \dfrac{\chi^2}{n}}=\sum_j{c_j \sum_i{ \left(\dfrac{p_{ij}}{c_j} -r_i\right)^2}} \]
Allora:
- La statistica chi-quadro (\(\chi^2\)) è una misura complessiva della differenza tra le frequenze osservate in una tabella di contingenza e le frequenze attese calcolate sotto l’ipotesi di omogeneità dei profili di riga (o dei profili di colonna).
- L’inerzia (totale) di una tabella di contingenza è la statistica (\(\chi^2\)) divisa per il totale di tabella \(n\).
- Geometricamente, l’inerzia misura quanto i profili di riga (o i profili di colonna) sono “distanti” dai loro profili medi. Il profilo medio può essere pensato come il rappresentante dell’ipotesi di omogeneità (cioè, uguaglianza) dei profili.
- Le distanze tra profili sono misurate usando la distanza del chi-quadro (distanza \(\chi^2\)). Questa distanza è simile nella sua formulazione alla distanza euclidea tra punti in uno spazio fisico, eccetto per il fatto che ogni differenza quadratica tra coordinate è divisa per il corrispondente elemento del profilo medio.
- L’inerzia può essere riscritta in una forma che può essere interpretata come la media ponderata delle distanze \(\chi^2\) al quadrato tra i profili di riga e il profilo di riga medio (equivalentemente, tra i profili di colonna e la loro media). Ora quindi definiamo: \[ D_r=diag(\underline{r}) \\ D_c=diag(\underline{c}) \\ P=\dfrac{1}{n} \cdot X = \{p_{ij}\} \]
In termini quanto possibile semplici, l’obiettivo della CA è trovare combinazioni lineari indipendenti di \(\underline{a}_i\) (\(\underline{b}_j\)) che massimizzano la distanza tra le combinazioni lineari stesse. I pesi delle combinazioni lineari sono vincolati ad avere lunghezza unitaria (altrimenti non si potrbbe avere una soluzione unica).
Per ottenere la soluzione, data la matrice seguente: \[ S=D_r^{-\frac{1}{2}}\left( P- \underline{r}\underline{c}^T\right)D_c^{-\frac{1}{2}} \] la si deve scomporre tramite SVD in: \[ S = U D_\alpha V^T; \text{ dove } U^T U =I \text{ e } V^T V = I \]
dove \(D_\alpha\) è la matrice diagonale dei vaori singolari (positivi) in ordine decrescente, e le quantità
\[ \Phi=D_r^{-\frac{1}{2}} U; \phantom{ aaa } \Gamma=D_c^{-\frac{1}{2}} V; \phantom{ aaa } F=D_r^{-\frac{1}{2}} U D_\alpha = \Phi D_\alpha; \phantom{ aaa } \Gamma=D_c^{-\frac{1}{2}} V D_\alpha= \Gamma D_\alpha \]
sono, rispettivamente, le Coordinate standard delle righe, le Coordinate standard delle colonne, le Coordinate principali delle righe e le Coordinate principali delle colonne.